 QQ咨询
QQ咨询 阿里旺旺
阿里旺旺 #skype#
#skype#
利用Mycat中间件实现RDS MySQL的分库分表及读写分离功能
随着移动互联网的兴起和大数据的蓬勃发展,系统的数据量正呈几何倍数增长,系统的压力也越来越大,这时最容易出现的问题就是服务器繁忙,我们可以通过增加服务器及改造系统来缓解压力,然后采用负载均衡、动静分离、缓存系统来提高系统的吞吐量。然而,当数据量的增长达到一定程度的时候,增加应用服务器并不能明显地提高系统的效率,因为所有压力都会传导到数据库层面,而大多数系统都是用一个数据库来存储和管理系统数据的,因而一个支持高性能、高并发并且易于扩展的数据库系统变的尤为重要。
Amazon RDS是AWS上托管的关系型数据库服务,目前支持业界主流的MySQL、Oracle、SQL Server、PostgreSQL、MariaDB引擎及AWS提供的Aurora,通过多可用区主备及读副本等技术,能够支持绝大部分的应用场景。
对于更大容量的数据库,可以使用Amazon Aurora,Aurora是一个关系型数据库引擎,结合了高端商用数据库的速度和可用性,同时还具有开源数据库的简单性和成本效益。Amazon Aurora 的设计与 MySQL 5.6 及PostgreSQL 9.6.1兼容,它提供的性能比同一硬件上运行的标准 MySQL 最多高达五倍,比PostgreSQL最多高达二倍。
下表是单个数据库实例能够支持的存储容量大小:
| RDS数据库引擎 | 存储容量 |
| MySQL | 6TB |
| Oracle | 6TB |
| PostgreSQL | 6TB |
| MariaDB | 6TB |
| SQL Server | 4TB |
| Aurora | 64TB |
不过由于Aurora目前并未在所有region提供,比如中国北京,同时支持的引擎有限,对于中国区用户及使用其他数据库引擎的用户,不得不考虑其他的解决方案。随着近年来海量数据存储、并行计算、异构数据互联等一系列新技术在市场上不断出现。相信数据库行业的很多从业者都对传统关系型数据库的单点故障及容量问题头疼不已,而数据库分库分表也早已成为解决此类问题的基础。
本文要介绍的Mycat是一款面向企业级应用的开源数据库中间件产品,支持事务、ACID,能够对接Oracle、MySQL、DB2、SQL Server、MongoDB、SequoiaDB等数据库,支持透明的读写分离机制,支持各种MySQL集群,包括标准的主从异步集群、MySQL Galera Cluster多主同步集群等,通过大表水平分片方式支持100亿级大表的分布式存储和秒级的并行查询能力,内建数据库集群故障切换机制,实现自动切换,可满足大部分应用的高可用性要求。
配置步骤:
第一步 创建RDS数据库实例
创建一个RDS将会使用的参数组mycat
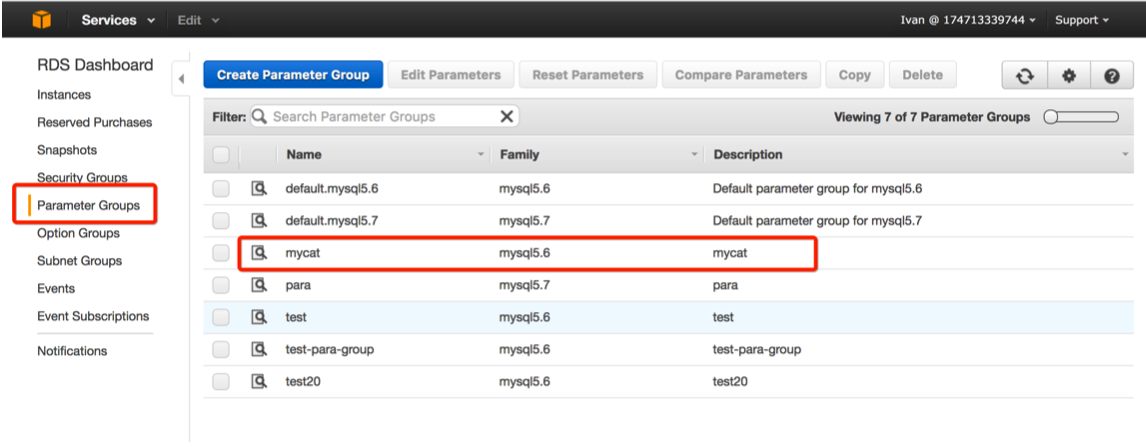
在分库分表的情况下,Mycat可以通过如下几种方式保证自增主键的全局唯 一:
1. 本地文件方式
在sequence_conf.properties文件中设置主键的当前值,最小值和最大值
2. 数据库方式
在其中一个 MySQL 节点中建立一张表,存放 sequence 的名称,当前值,步长 等信息,并通过存储过程修改更新信息
3. 本地时间戳方式
4. 注解方式
本例使用第二种方式,为了使存储过程能够顺利执行,需要修改参数组的log_bin_trust_function_creators为1
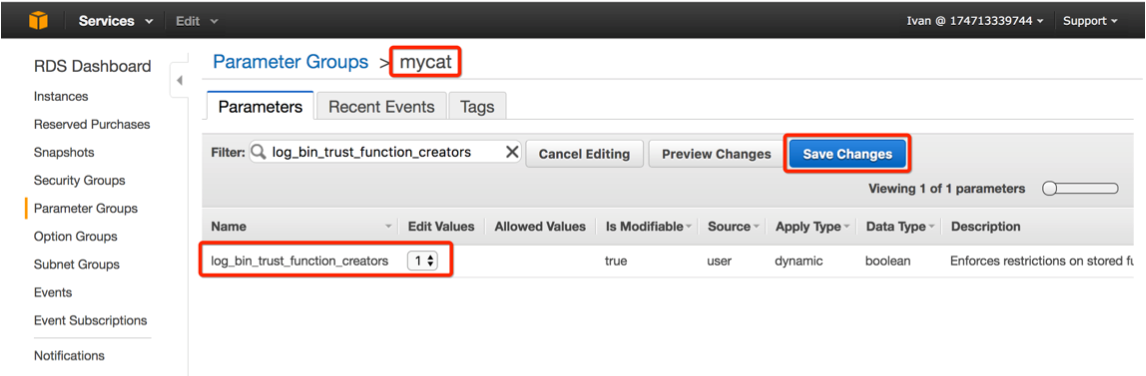
此外,可以按需设置时区及大小写不敏感


接着创建两台 RDS MySQL 实例,注意需要在创建的时候选择 mycat 参数组
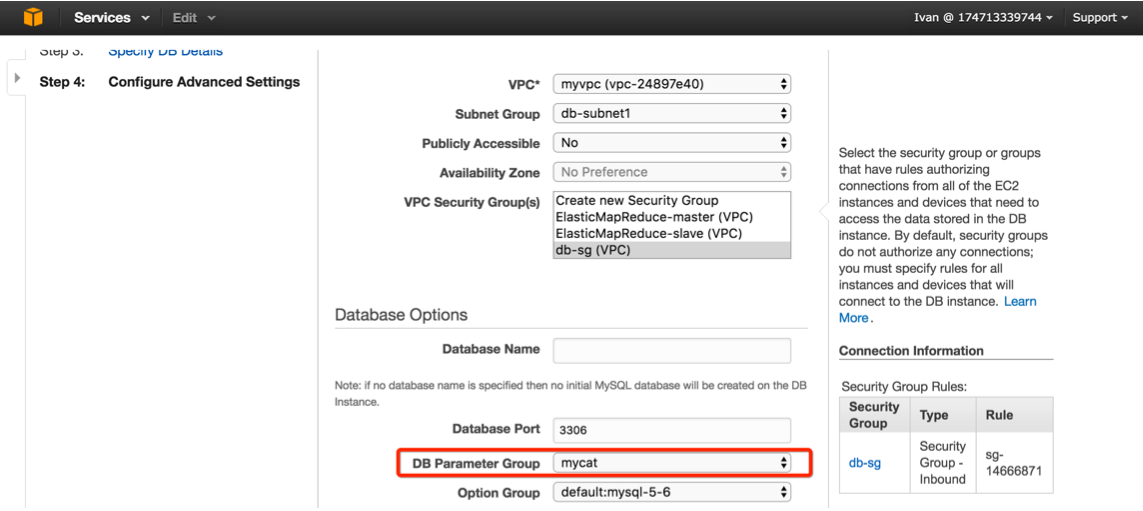
本例使用 MySQL 5.6.34 版本,开启 Multi-AZ 及自动备份功能,并且为每个 MySQL RDS实例创建一个读副本做读写分离

数据库 endpoint 如下:
mysql1
mysql1.cbqbpwftrsrj.rds.cn-north-1.amazonaws.com.cn
mysql1-read-replica
mysql1-read-replica.cbqbpwftrsrj.rds.cn-north-1.amazonaws.com.cn
mysql2
mysql2.cbqbpwftrsrj.rds.cn-north-1.amazonaws.com.cn
mysql2-read-replica
mysql2-read-replica.cbqbpwftrsrj.rds.cn-north-1.amazonaws.com.cn
第二步 安装配置 Mycat
本例使用 Cento 6.7 创建 EC2
1. 安装epel及mysql源
rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
rpm -ivh https://repo.mysql.com//mysql57-community-release-el6-9.noarch.rpm
2. 修改/etc/yum.repos.d/mysql-community.repo如下

3. 安装相关软件包
yum update -y
yum install mysql-server java-1.8.0-openjdk.x86_64 vim wget -y
4. 下载并安装Mycat
wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
tar xzvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
5. 配置Mycat中间件
5.1 vim mycat/conf/server.xml
该配置文件主要用于创建 mycat 用户及 mycat 的系统参数设置,这里只列出保证mycat正常工作的参数配置,其中还有很多优化项需要读者根据需要自行修改,具体可以参考文末的参考书及链接
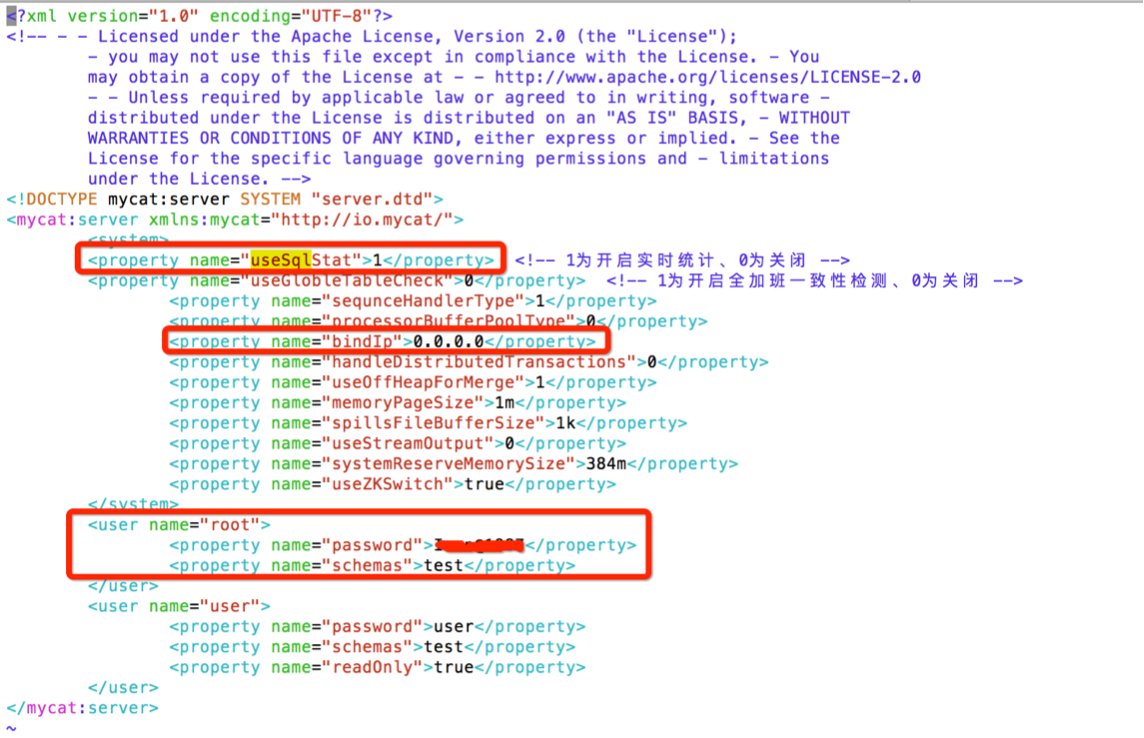
其中 sequenceHandlerType 为1表示使用数据库方式实现自增主键
5.2 vim mycat/conf/schema.xml
该配置文件主要用于配置逻辑库、表、分配规则、分配节点及数据源,同样这里的配置并不包括参数优化在内
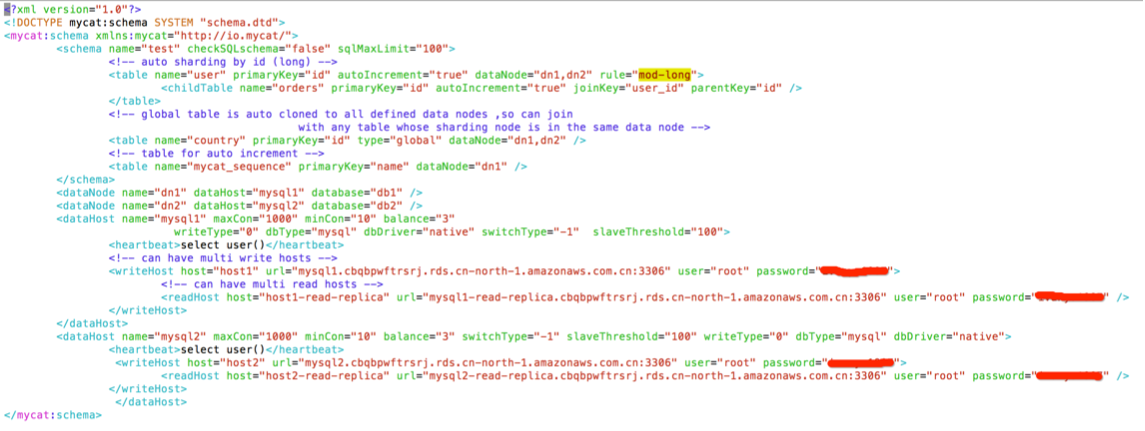
上面配置有几个地方需要注意
1. 分片dn1和dn2分别对应于mysql1中的db1和mysql2中的db2,需要事先登入这两台 RDS 实例,并分别创建 db1 和 db2 数据库
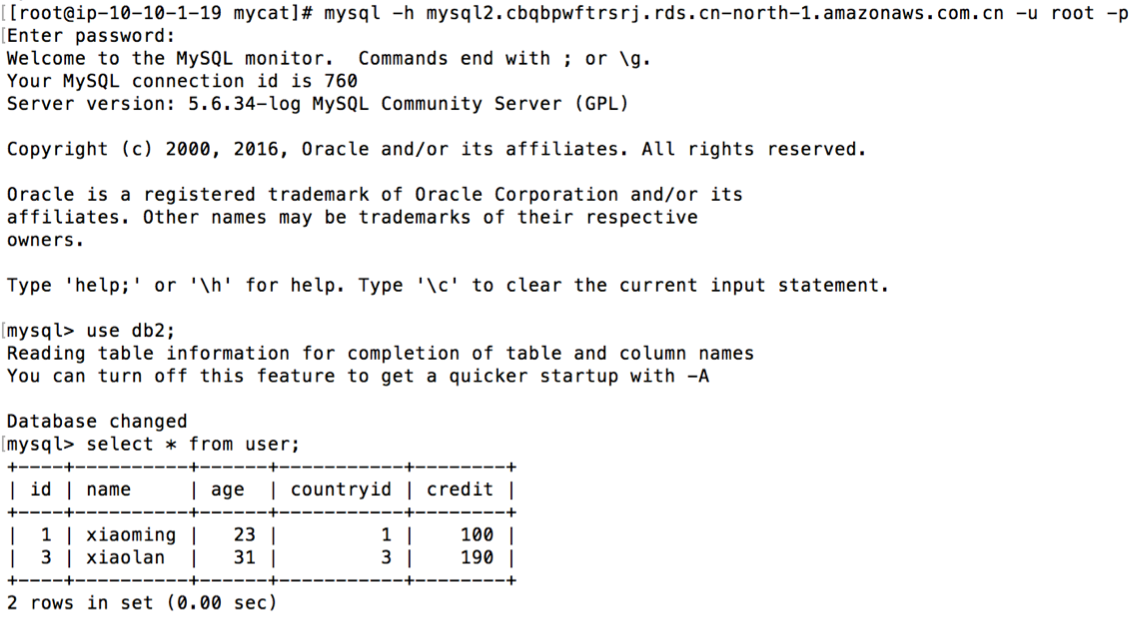
2. user表会在两台RDS实例中分片,基于id字段,使用mod-long算法进行分片
3. orders 表作为 user 表的子表,使用 ER 关系表进行分片,是 Mycat 中避免跨库join 的其中一种方式,适用于有父子关系的两张表,这里 orders 表中的user_id 字段对应于 user 表中的 id 字段,当需要对 orders 表进行插入操作的时候,Mycat 会对 user_id 应用父表的 mod-long 算法找到具体的分片并插入,这样 order 表和user 表基于user.id=orders.user_id 的 join 操作可以在每个分片中进行,无需跨库
4. country表的type为global,设置为全局表,也就是在每个RDS实例中均有完整的 country 表信息,是 Mycat 中另外一种避免跨库 join 的方法,适用于内容较为固定,数据量不大的字典表
5. dataHost标签中的balance为3,实现读请求完全到readHost上进行
6. dataHost标签中的switchType为-1,意思是当writeHost故障的时候不进行切换,这是针对 RDS 特有的配置,由于 RDS 已经启用了 Multi-AZ 的功能,主库故障会自动切换到 standby 实例,无需 Mycat 切换到某台readHost
7. user,password为具体RDS实例的登入用户账号
8. user表和orders表设置了autoIncrement=true主键自增
9. mycat_sequence表用于存储其他表的自增主键信息
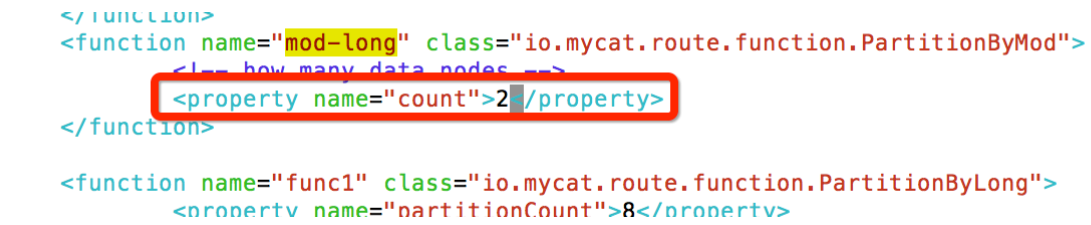
5.3 vim mycat/conf/rule.xml
该配置文件主要用于定义分片算法,由于本例使用两台 RDS实例,需要将 mod-long 分片算法的 data nodes 参数设成 2
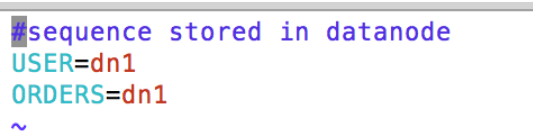
5.4 vim mycat/conf/sequence_db_conf.properties
该配置文件用于设置主键自增表的自增信息,这里将 user 表和 orders 表的自增信息存到 dn1,也就是 RDS mysql1 中,注意这里的 USER,ORDERS 需要大写
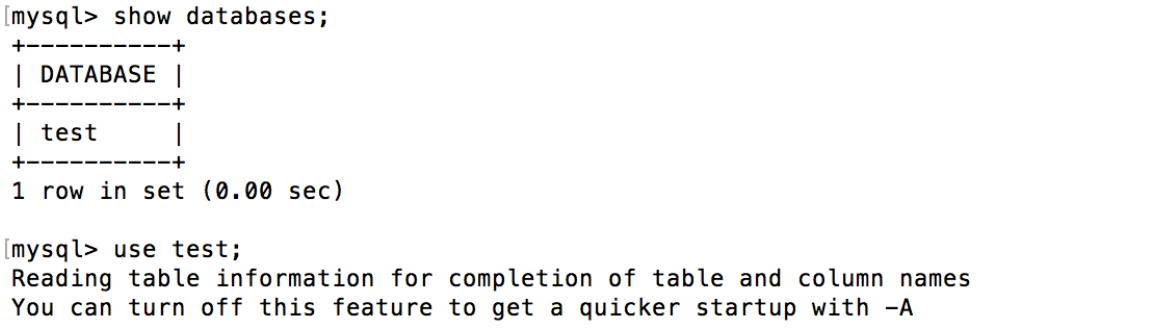
5.5 启动 Mycat,并建表
./mycat/bin/mycat start &
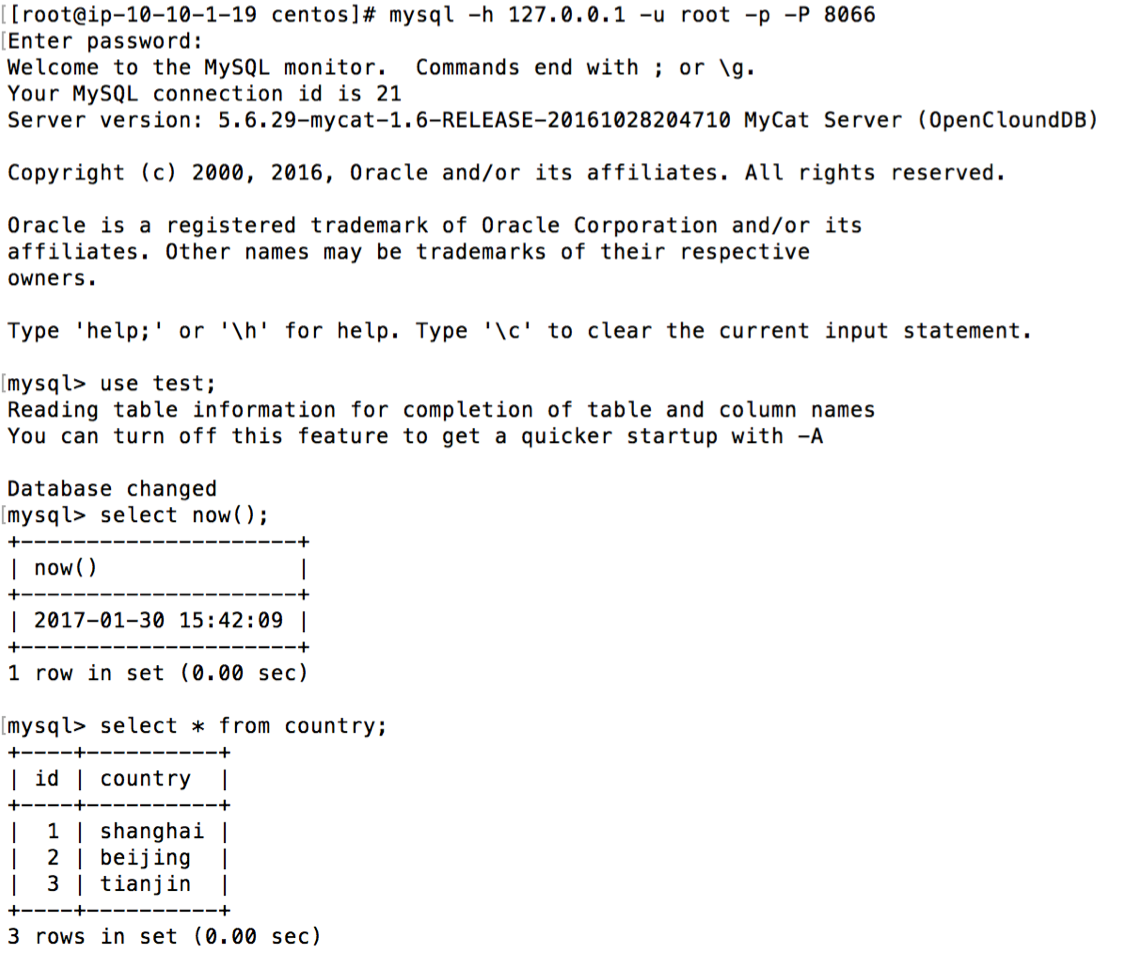
mysql –h 127.0.0.1 –u root –p –P 8066
show databases 可以看到定义的逻辑库 test
下面是具体的建表语句


下面设置 user 表及 orders 表的自增主键的当前值为0,自增步长为1

5.6 配置实现主键自增的存储过程
存储过程需要在具体的 RDS 实例上创建,在这里是 RDS mysql1
mysql –h mysql1.cbqbpwftrsrj.rds.cn-north-1.amazonaws.com.cn -u root –p

第三步 功能验证
1. 登入Mycat
mysql –h 127.0.0.1 –u root –p –P 8066 use test;
2. 验证主键自增
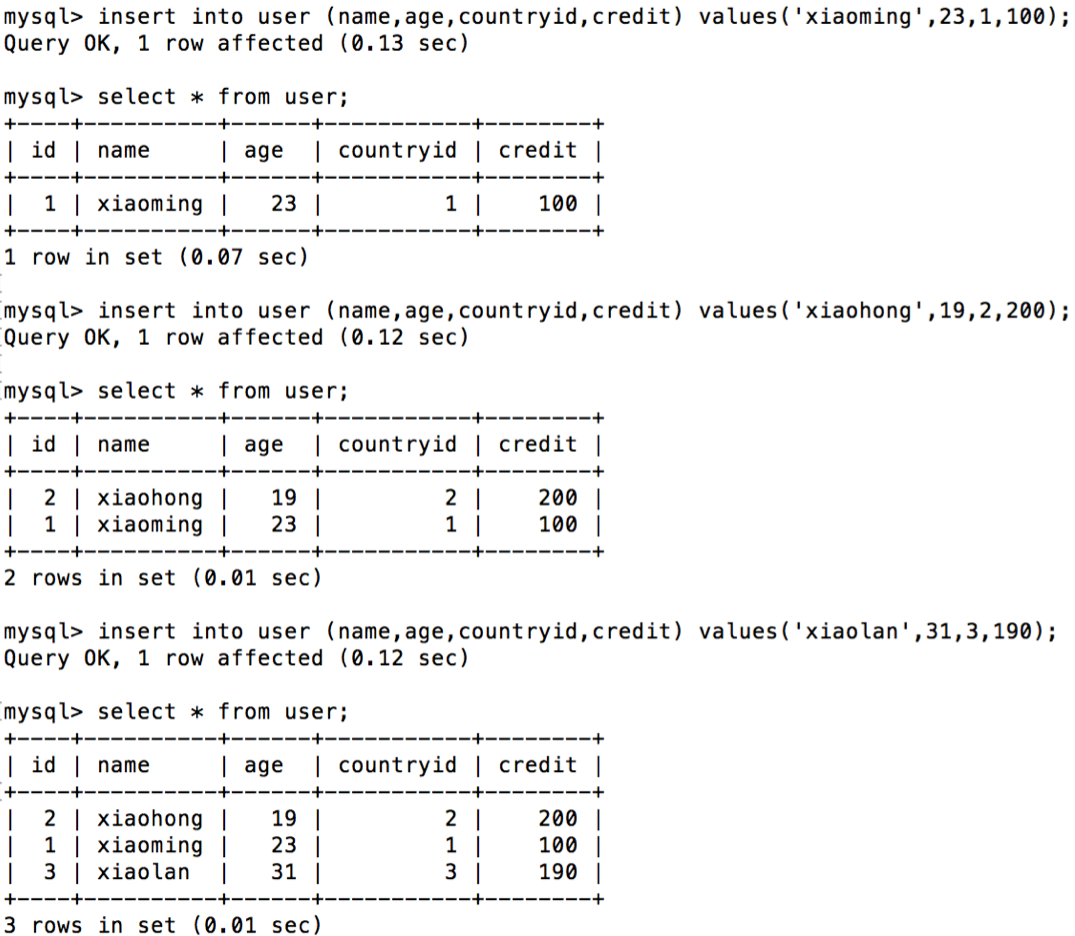
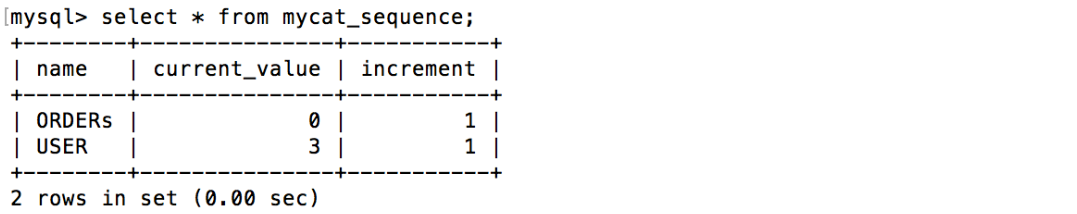
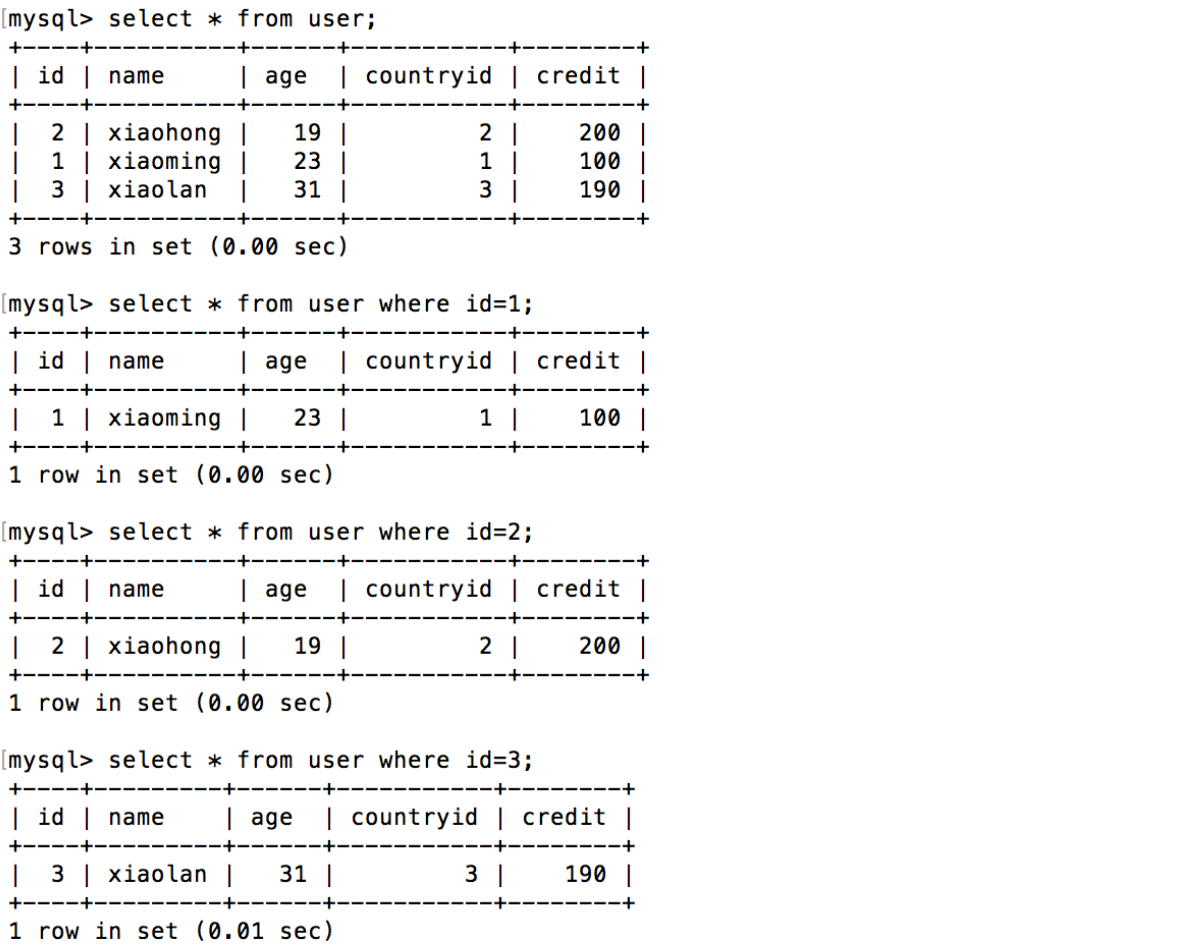
3. 验证user表在两台RDS实例中分片

4. 验证country表为全局表,并且能够和user表做join
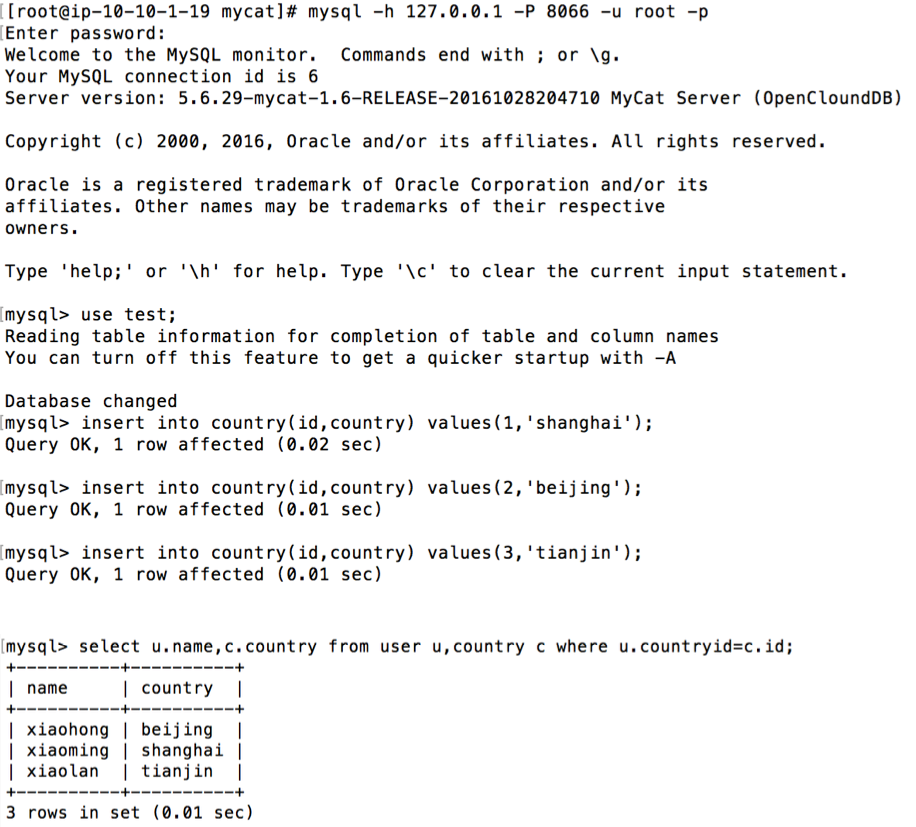
在两台 RDS 实例上可以看到 country 表的全部内容
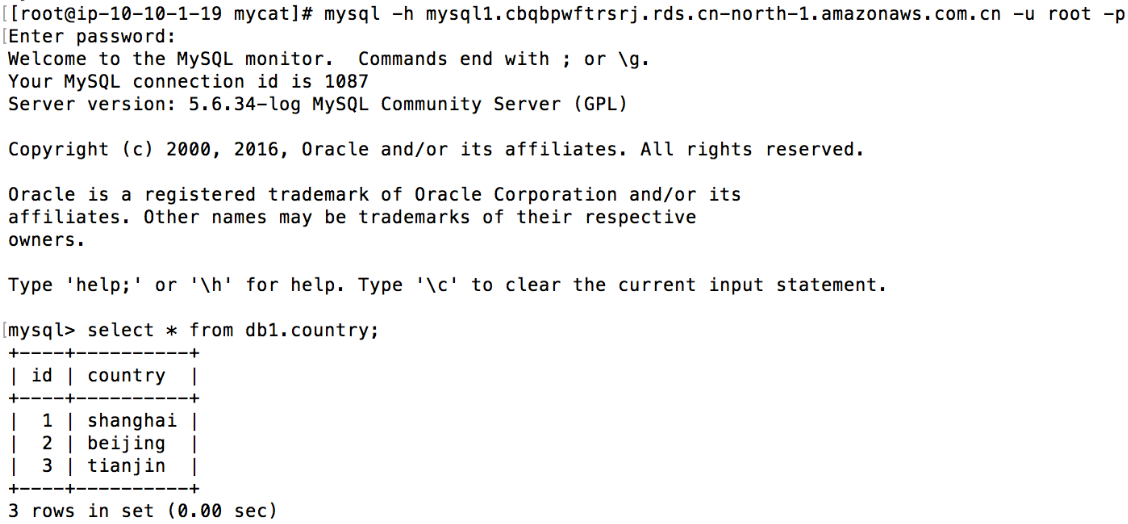
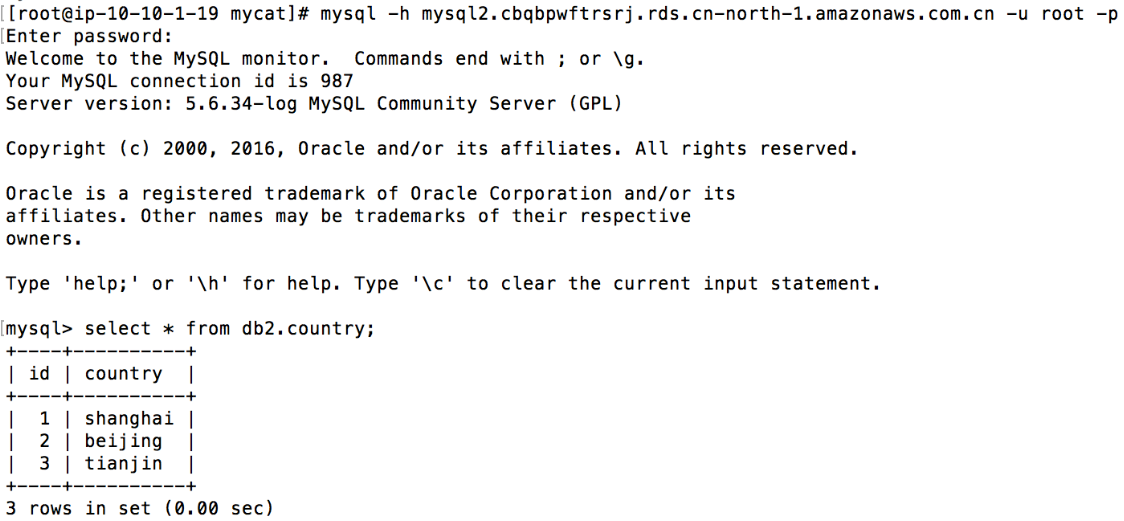
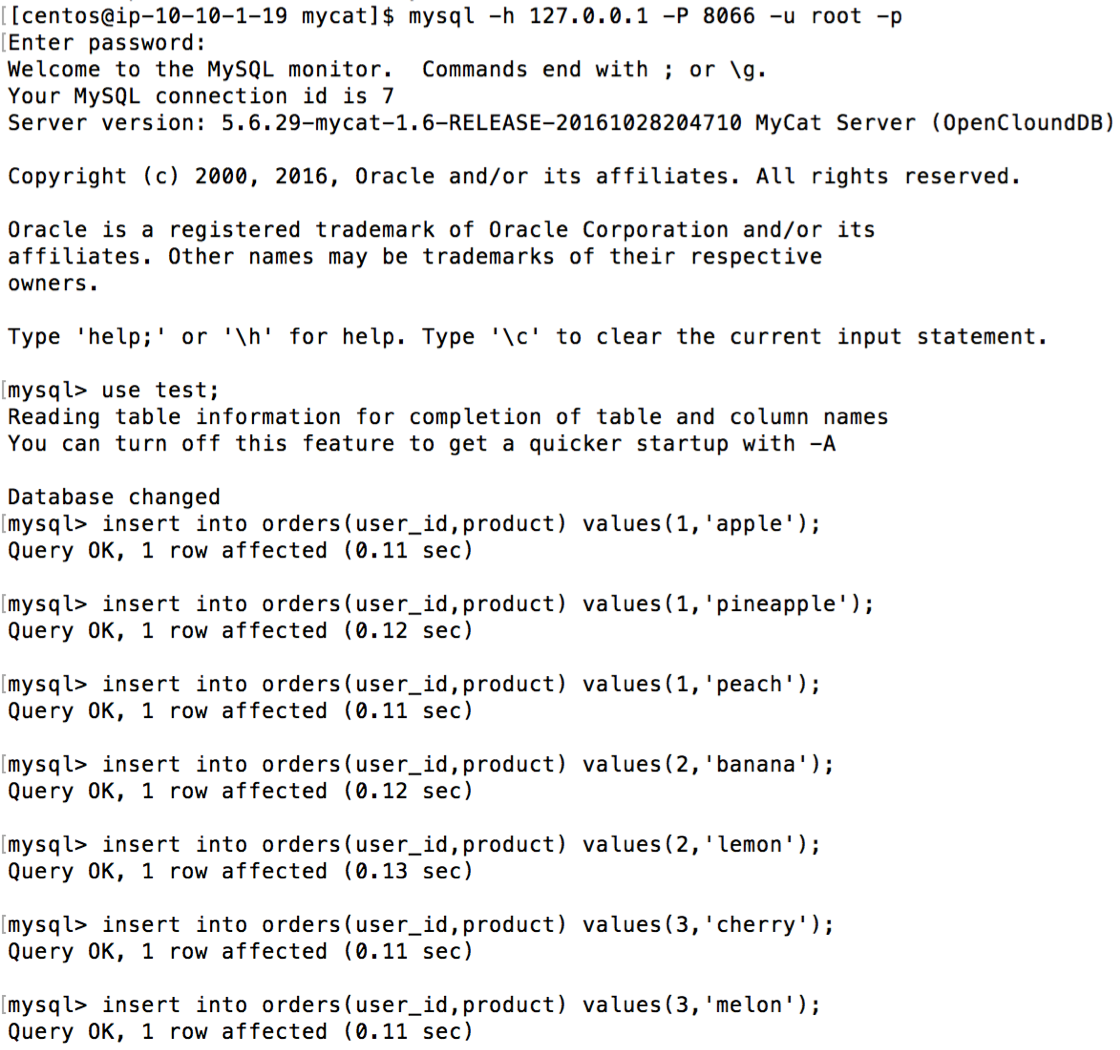
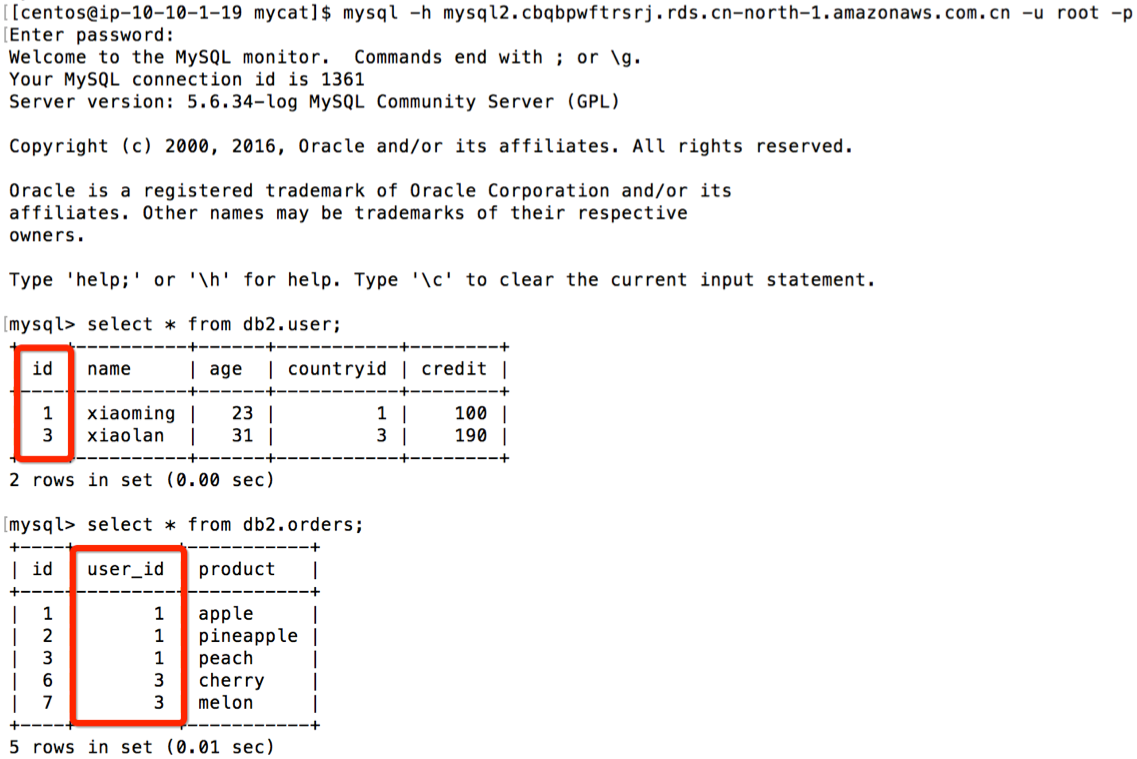
5. 验证 orders 表的分片规则关联父表 user 表,即 orders 表中的 user_id 与 user 表中 id字段相等的行存储在同一个 RDS 实例中,并且两张表能够 join

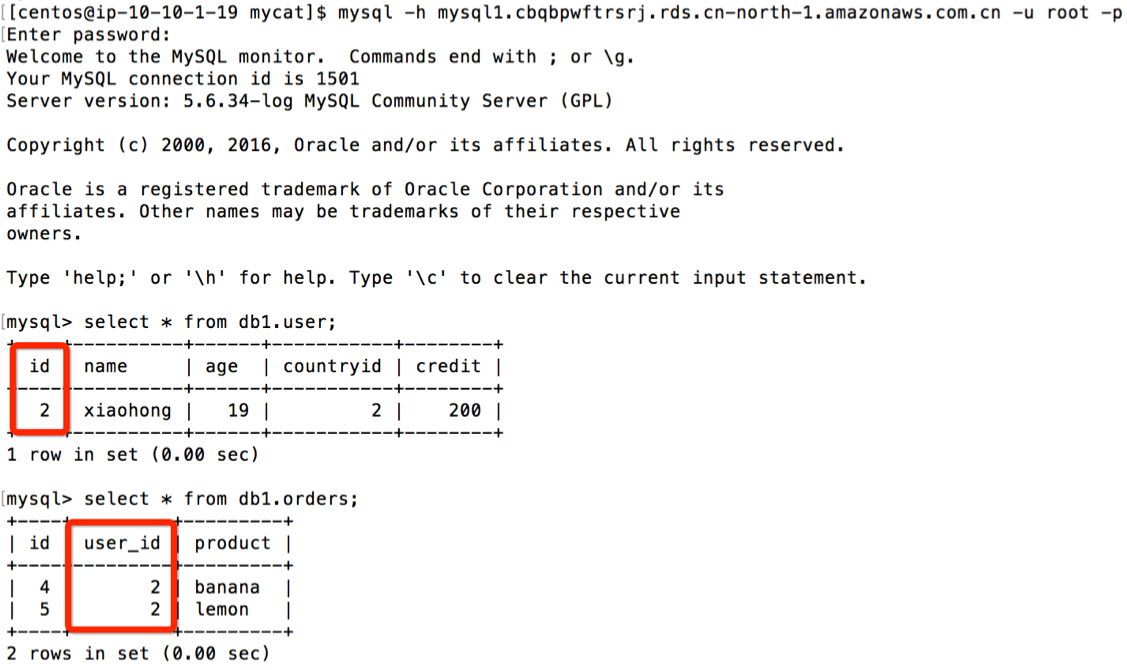
在两台 RDS 上查看到 user 表与 orders 表的存储关系
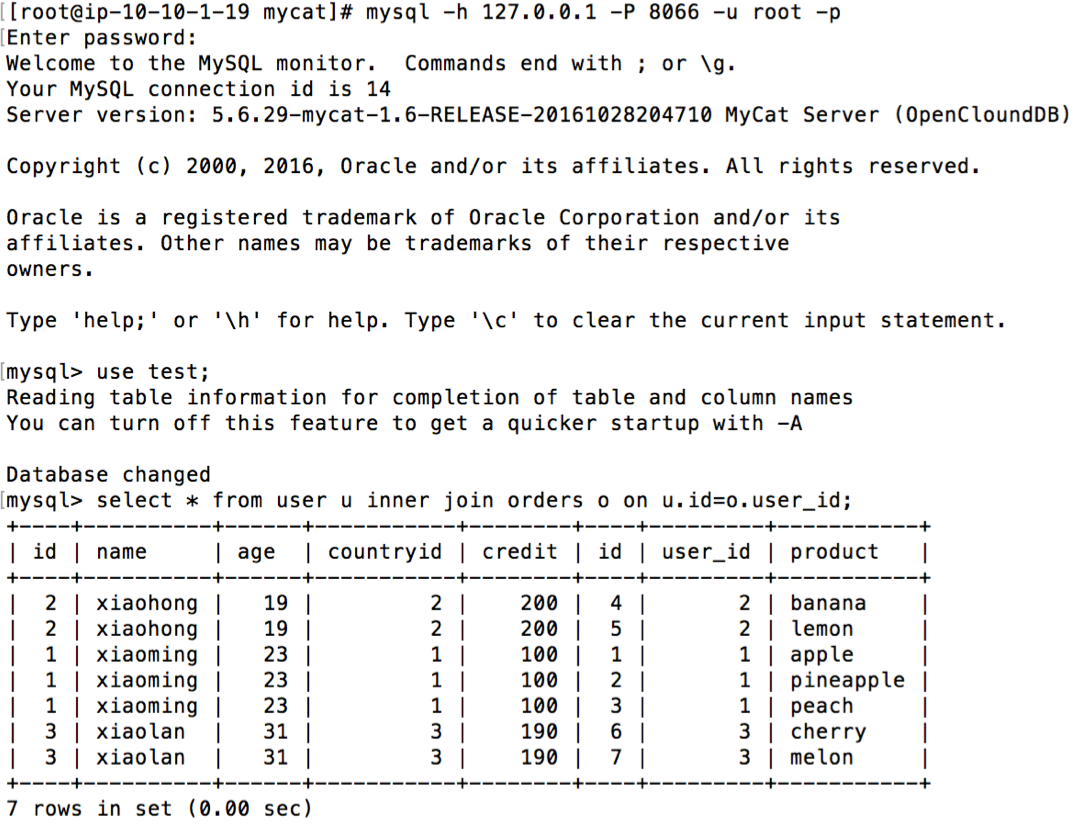
6. 验证使用ShareJoin实现分片join
如上两种方式本质上是通过全局表或者相同的分片规则规避分片 join,SQL语句经过 Mycat 分发到各个 RDS 节点本地 join,然后在Mycat 中进行结果的汇聚,如果两张表都比较大,不适合作为全局表并且表与表之间没有类似的父子关系时,有两种方式解决
1. 增加冗余列,即人为在两张表中构建相同的两列,比如上例的 user.id 和orders.user_id,然后基于这两列来分片
2. 通过ShareJoin注解,ShareJoin本质上是将一条join语句拆分成单表的SQL语句,然后把各个节点的数据汇集
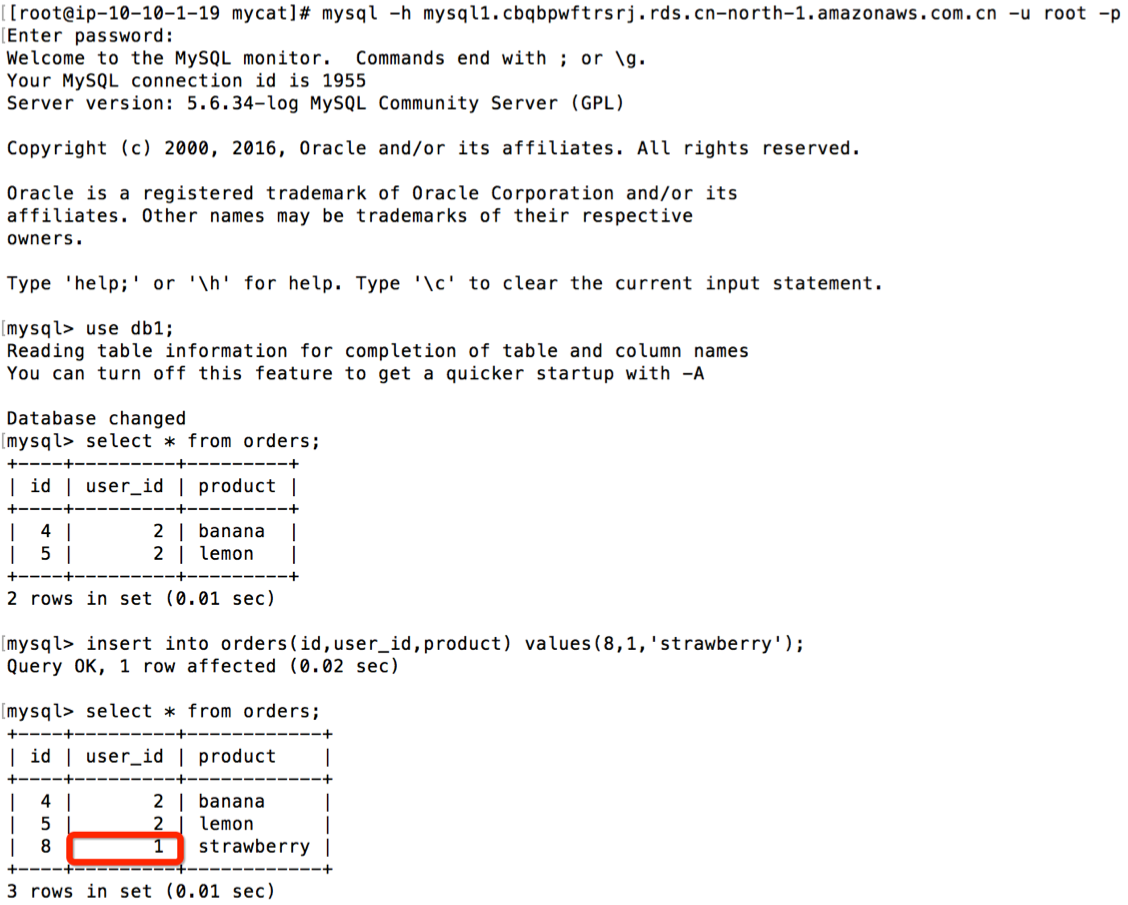
登入 RDS mysql1,对 orders 表人为插入一条 user_id 为奇数的信息,使得 orders 表的分片规则与 user 表的出现
此时再使用 join 语句将会丢失刚刚插入的那一行,因为 RDS mysql1 在本地执行 join 语句时,本地 user 表中并没有 user.id=1 的条目
通过在 SQL 语句前加上 ShareJoin 的注解,实现跨分片 join 功能
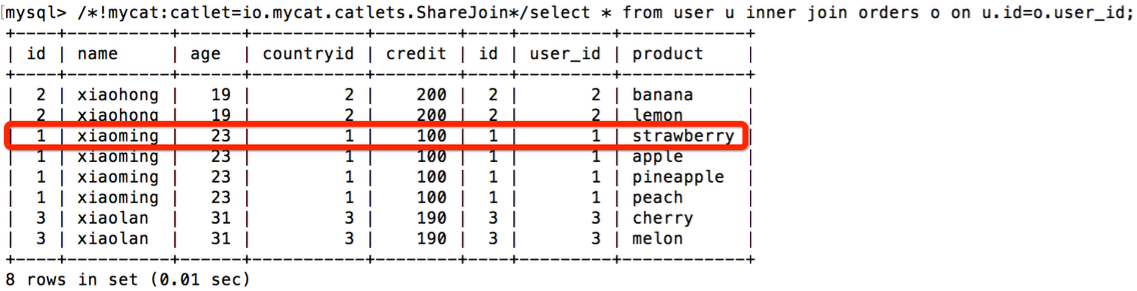
笔者在实际使用过程中发现,ShareJoin 并不是总能够正常工作,怀疑可能是 bug 或者语句限制,不到万不得已,建议使用上面的两种方式来规避跨库 join,比如上面的语句如果只是取出某几列,ShareJoin 并不总能正确输出
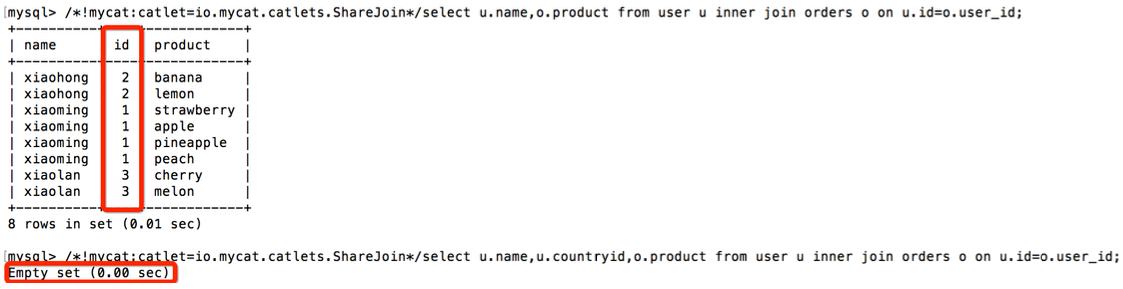
另外还有一种 Mycat 支持的跨分片join技术是 catlet,也叫做人工智能(HBT), 主要是参考了数据库中的存储过程的实现方式,需要用户根据系统提供的 API 接口在代码中实现跨分片 join,具体可以参考文末的参考书中的内容
7. 验证读写分离
修改 RDS 参数组 mycat,开启 general log
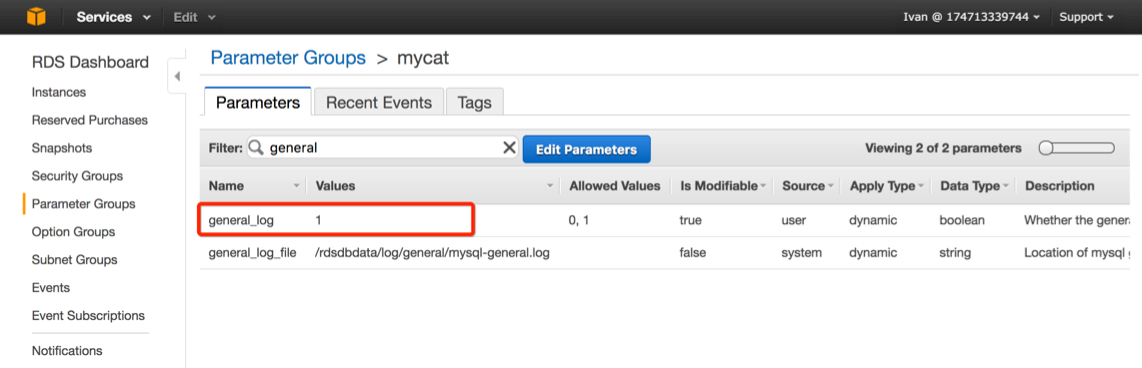
注意:开启 general log 会影响数据库的性能并占用存储空间,不建议在常规时间开启,这里只是用于验证
登入 Mycat,执行如下语句,可以看到在15:42:09-15:42:29的时间段内,一共执行了两次对 country 表的全表扫描,一次 user 表的全表扫描,和三次 user 表的单行查询,需要验证的结果如下:
1. 由于country表是全局表,只会在一台实例上执行,所以两台read-replica中一共可以看到两条语句
2. user表是分片表,所以全表扫描会在每台read-replica中看到一条语句
3. user表的单行扫描会按照Mycat的分片规则分配到相应的read-replica中执行
4. 所有语句不会出现在mysql1和mysql2写库的日志中


分别登入 mysql1,mysql2,mysql1-read-replica,mysql2-readreplica 执行 select * from mysql.general_log,查看 15:42:09-15:42:29 时间段内的日志
mysql1,mysql2 中没有执行的语句日志
mysql1-read-replica 中,可以看到两条 country 的全表扫描,一条 user 的全表扫描和user 表 id 为 2 的查询语句,其中全表扫描的 limit 100 为 Mycat 自动添 加,可以通过配置修改
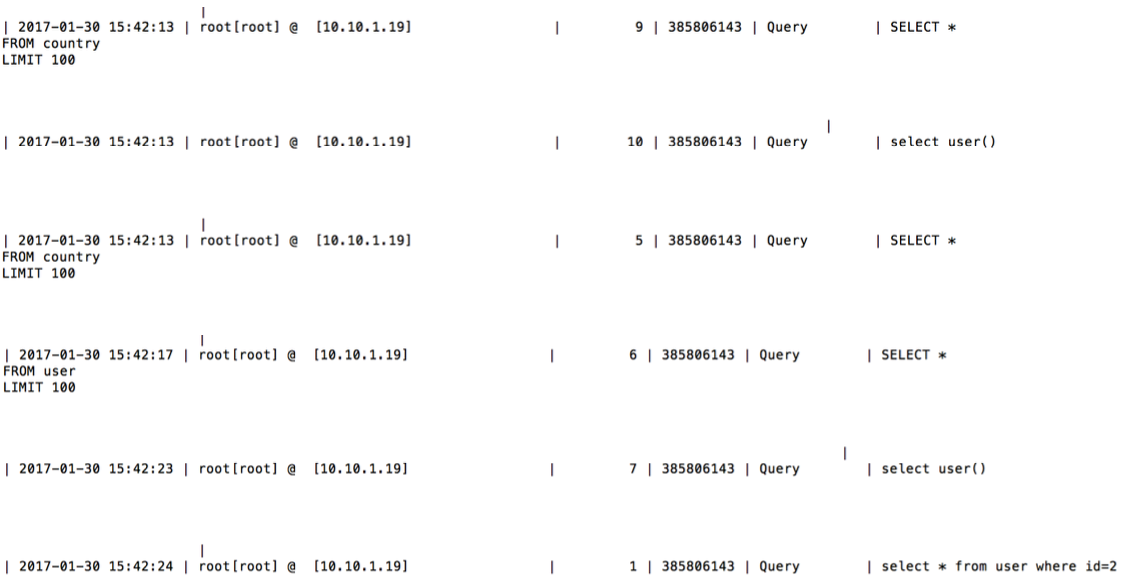
mysql2-read-replica 中,可以看到一条 user 的全表扫描和 user 表 id 为 1,3 的查询语句,其中全表扫描的 limit 100 为 Mycat 自动添加,可以通过配置修改

第四步 配置 Mycat 的冗余
1. 设置Mycat开机自启动
vim /etc/rc.local,添加如下启动指令
sh /home/centos/mycat/bin/mycat start
2. 根据需要设置iptables防火墙策略
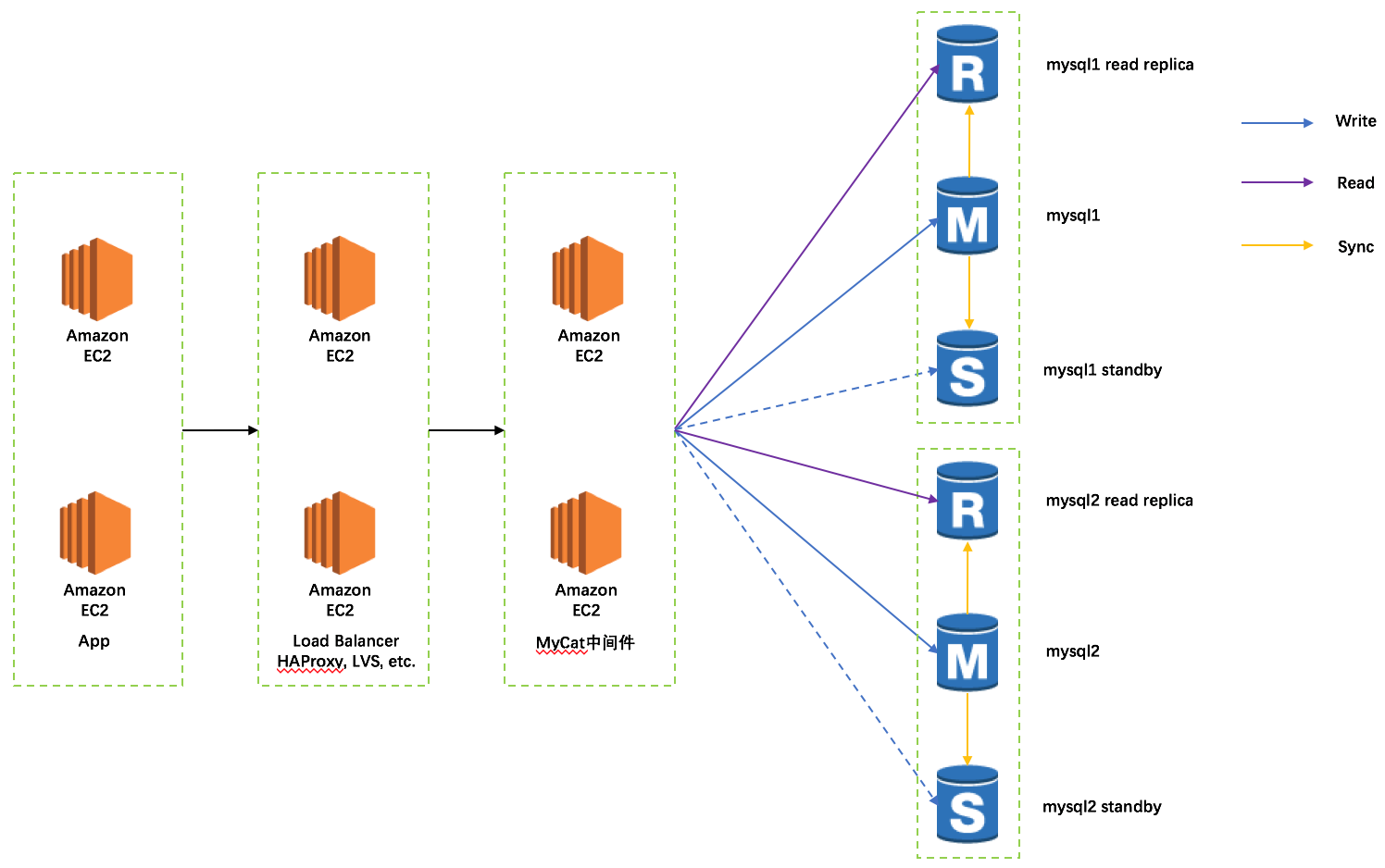
3. 创建 AMI,通过 AWS autoscaling-group,实现 Mycat 冗余及高可用,应用层对两台MyCat的负载均衡可以在应用层实现或者使用负载均衡器,由于这部分配置比较基础,此处不做详细介绍
最终拓扑图如下:
第五步 使用 Mycat-web 实现监控(可选)
Mycat-web为 Mycat 提供了一个基于 Web 的监控平台,功能非常丰富,可以对 Mycat实例,Mycat 所在机器的 JVM 以及具体的 MySQL 节点进行监控
1. 安装启动Mycat-web
本例使用一台独立的 EC2 安装,使用 Centos 6.7,配置 internet 可以访问
Mycat-web 依赖 zookeeper,需要先安装 zookeeper
wget http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper- 3.4.9.tar.gz
cd zookeeper-3.4.9/conf
mv zoo_sample.cfg zoo.cfg
cd ../bin
./zkServer.sh start &
安装 Mycat-web
wget http://dl.mycat.io/mycat-web-1.0/Mycat-web-1.0-SNAPSHOT- 20170102153329-linux.tar.gz
cd ~/mycat-web/WEB-INF/classes
vim mycat.properties
zookeeper=localhost:2181(默认已经修改)
cd ~/mycat-web
./start.sh &
2. 配置Mycat-web
通过浏览器访问 mycat-web
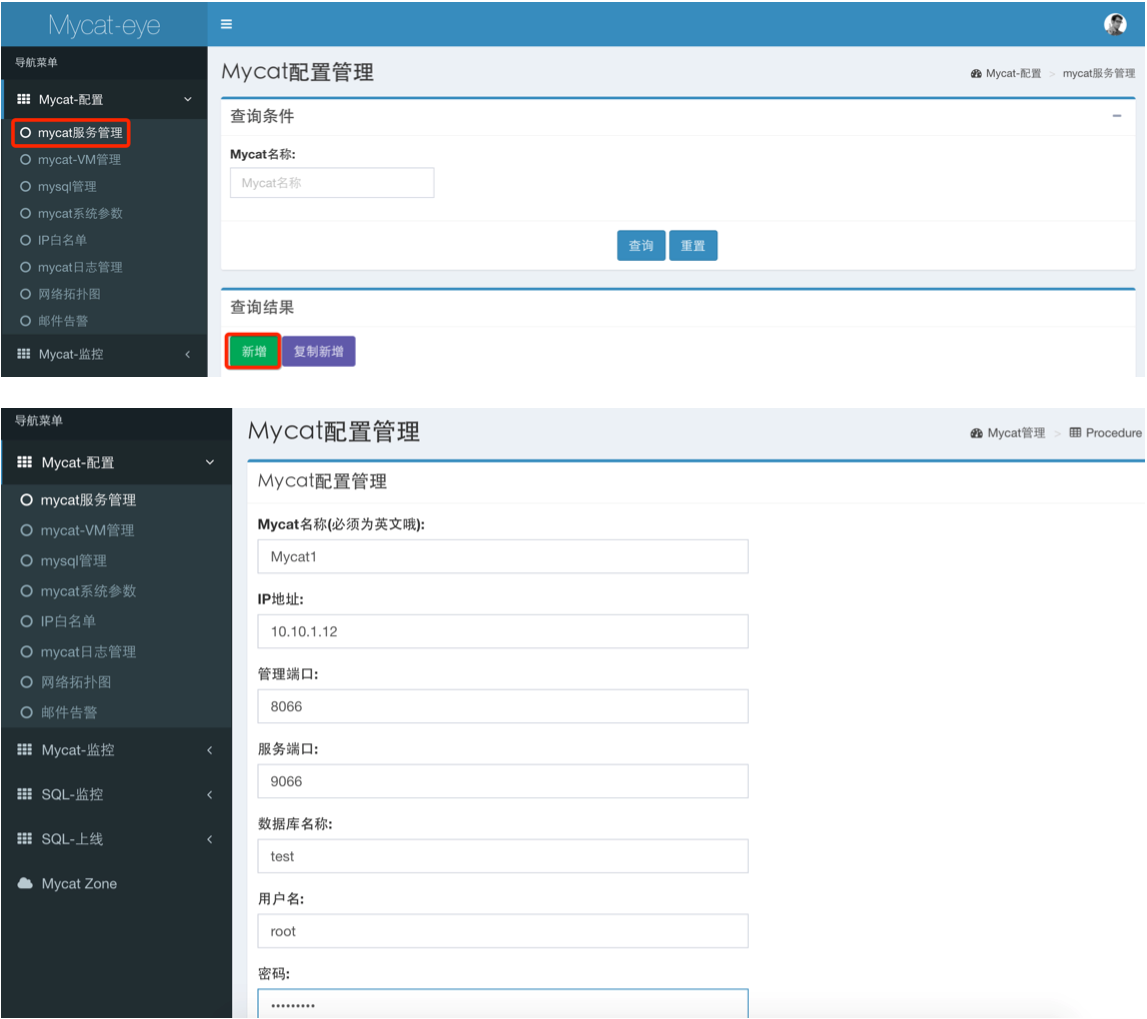
添加 Mycat 节点

添加 JVM 节点
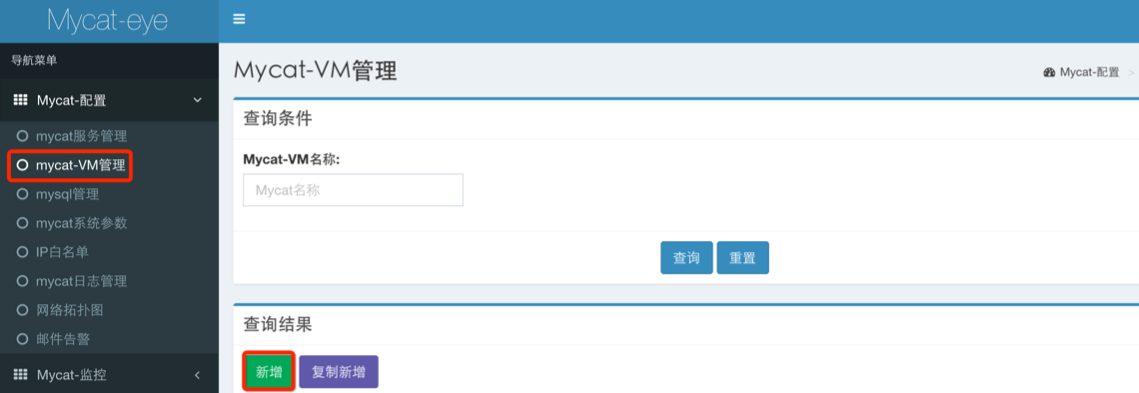

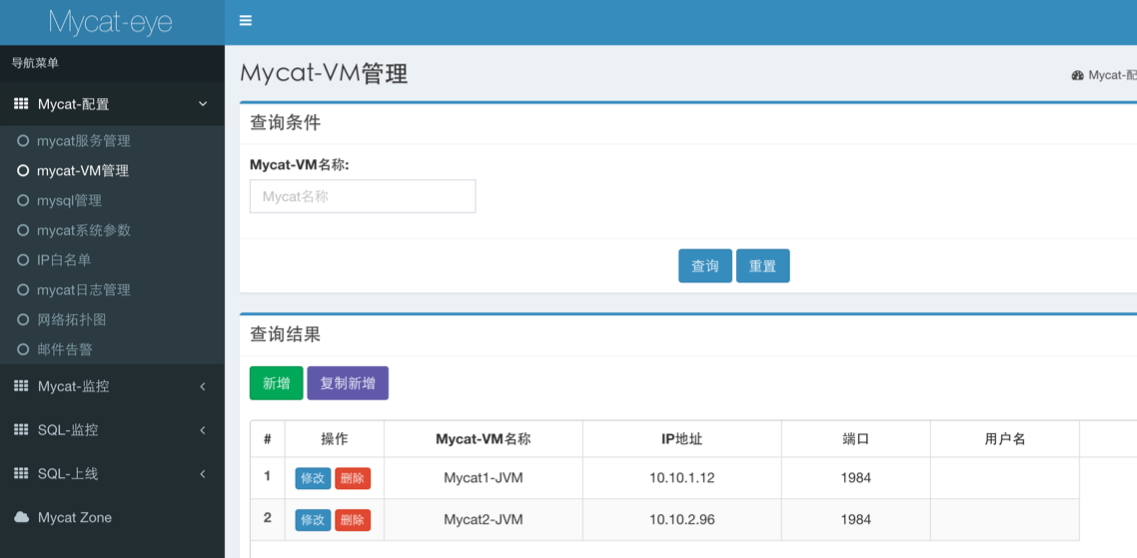
添加 MySQL 节点
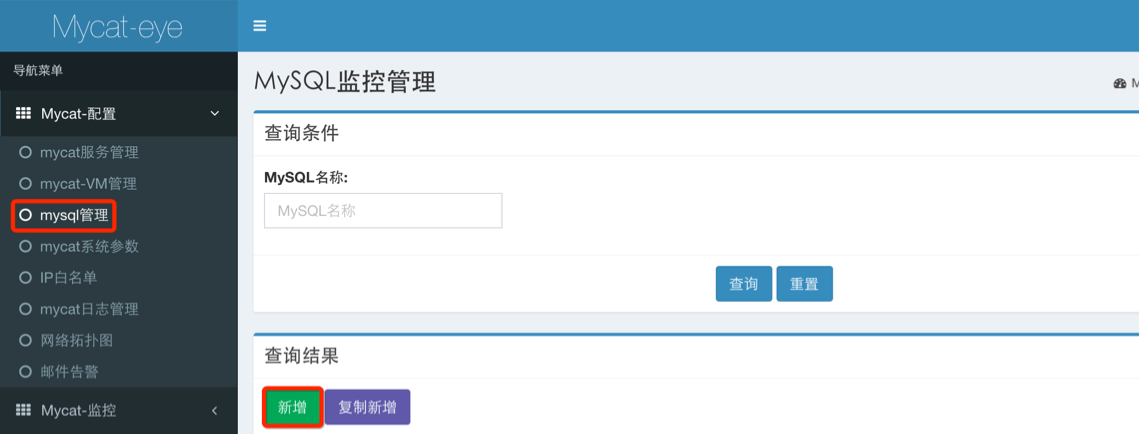

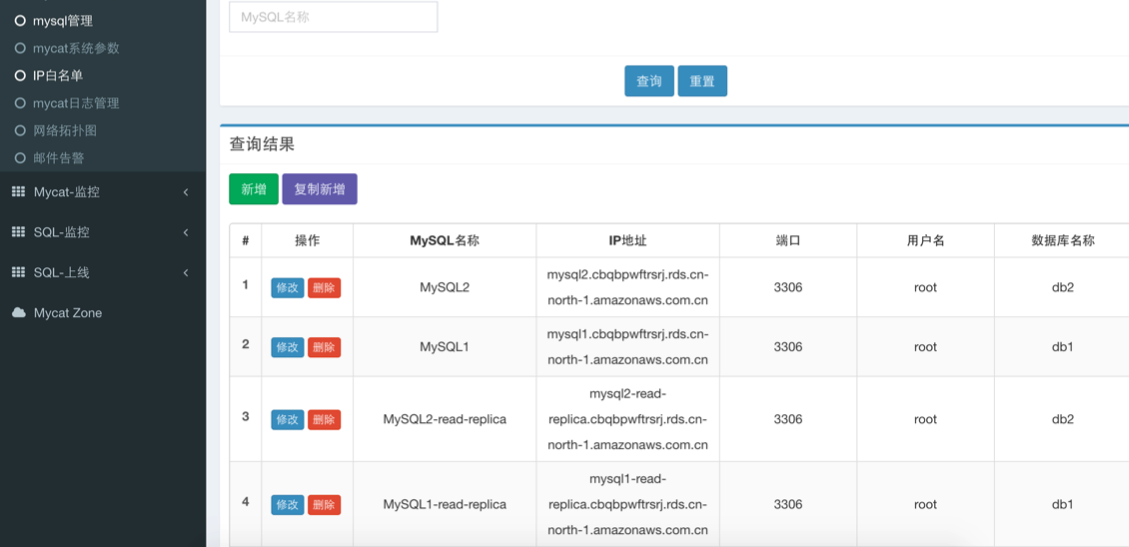
接下来就可以通过 Mycat-web 查看系统的各项参数
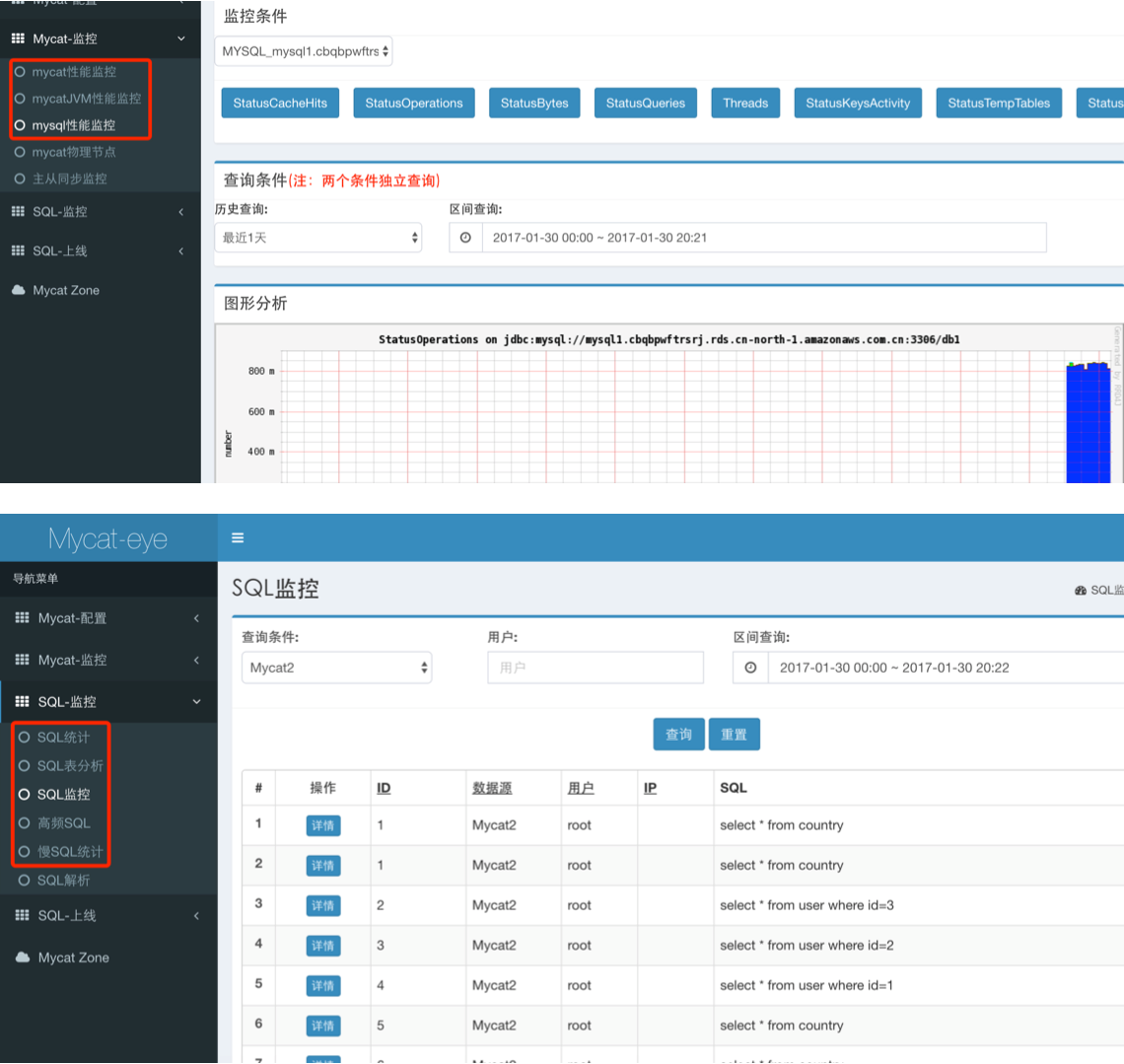
目前有一个问题,Mycat-web 只能够收集到 read 的操作,所有 insert/delete/update 等写操作无法收集
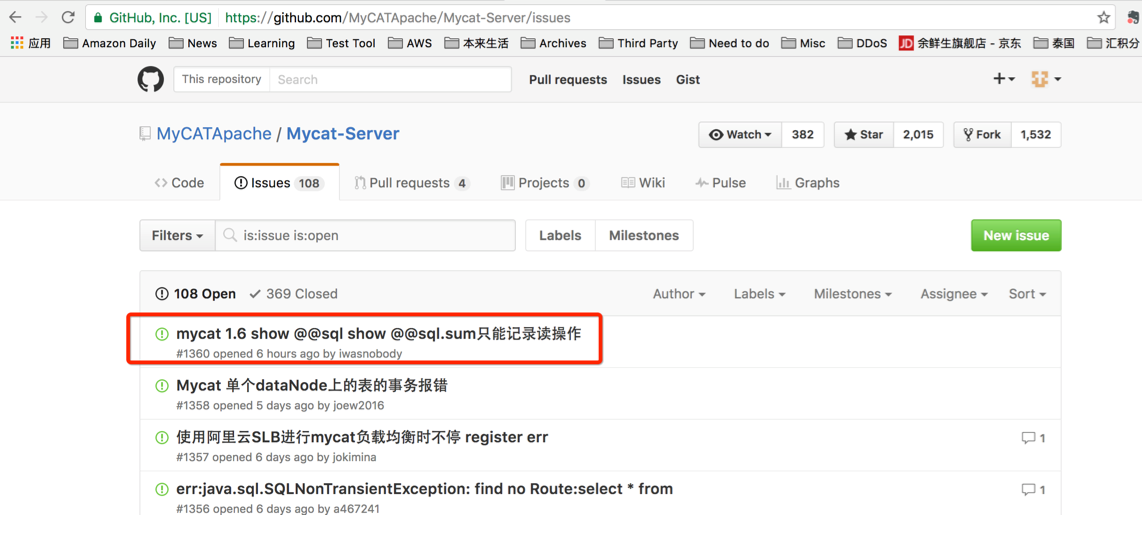
通过 Mycat 服务端口 8066 登入一台 Mycat,执行一系列 select 及 insert 读写操作,退出后通过管理端口 9066 登入,查看日志发现所有 insert 写操作并未记录到日志中,因此可以确定不是 Mycat-web 的问题,而是可能由于 Mycat 本身配置不当或者由于 bug 导致写操作没有记录到日志中,已经在 github 上提交 issue,等待答复中


参考内容:
《分布式数据库架构及企业实践:基于Mycat中间件》
Mycat 自增主键配置:
http://deweing.github.io/2016/06/29/mycat-auto-increment.html