QQ咨询
QQ咨询 阿里旺旺
阿里旺旺 #skype#
#skype#
利用 Kinesis Analytics 实时分析用户访问行为
随着时间的推移,大数据分析一词已经慢慢从一个概念进入到了实际应用的阶段,近年来,越来越多的企业已经不满足于定期批量地分析任务,为了更好地利用不断产生的业务数据,做出更快更有效的业务决策,实时数据分析已经成为了诸如电商,网站,交易平台的标准需求。
另一方面,自建实时分析平台无论从成本还是对技术人员的要求都相当巨大,大量的技术人员更喜欢使用SQL而非代码的方式来挖掘数据,基于此,AWS提供的Kinesis Analytics服务很好地满足了用户的需求,通过简单的SQL语句及内置的丰富函数,用户能够快速地搭建起适合自身业务场景的实时分析解决方案,所有的底层设施由AWS来维护,保证服务的高可用性,用户可以把更多地精力放在如何挖掘和分析数据的工作上。
本文以实际的应用场景出发,介绍如何通过使用AWS的服务,实时分析CloudFront的访问日志,同时,借助于DynamoDB的全局表功能,使得用户能够利用支持Kinesis Analytics的区域对日志进行分析,并把分析结果同步回用户现在使用的区域的DynamoDB表中,帮助那些使用尚未支持Kinesis Analytics区域的用户也能够使用并享受到该服务带来的便捷。
下面我们来看下方案的架构:
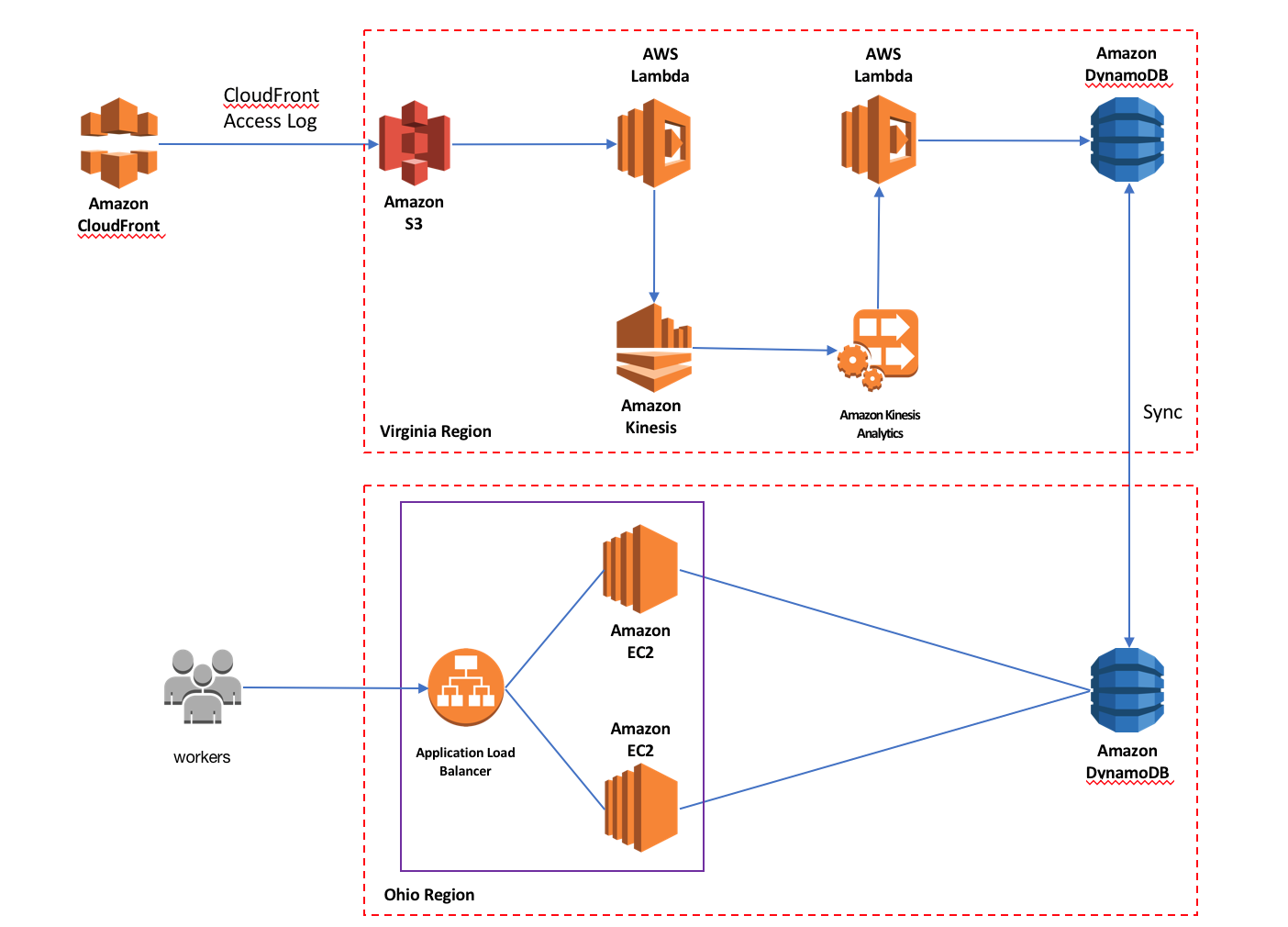
如上图所示:
· CloudFront会定期将用户的访问日志保存到用户设置的S3存储桶中。
· 日志在S3上生成后会自动触发Lambda函数。
· Lambda函数对日志进行解压缩,并将日志内容打入Kinesis Stream流中。
· Kinesis Analytics从Kinesis Stream流中获取日志数据并进行实时分析。
· Kinesis Analytics的分析结果会发送到另一个Lambda函数。
· 该Lambda函数将分析结果处理后存入本区域的DynamoDB表中。
· 由于启用了DynamoDB全局表,分析结果会自动同步到其他区域的DynamoDB表中。
· 在用户业务所在的区域中,通过使用ALB,EC2搭建简单的web应用就可以对DynamoDB表中的数据进行实时的分析展现。
本文假设用户业务所在的区域是Ohio,由于Ohio尚未支持Kinesis Analytics服务,因而将所有分析组件部署在Virginia区域,仅仅将分析结果同步回Ohio的DynamoDB表中,另外,对于图中的ALB,EC2部分,本文不做详细的搭建说明,用户可以使用自己熟悉的开发语言进行展示页面的开发,也可以使用API GW,Lambda搭建无服务器的展示系统。
那下面我们就来看看如何快速地搭建这样一个实时分析平台吧。
第一步 准备工作
首先开启CloudFront的日志功能。

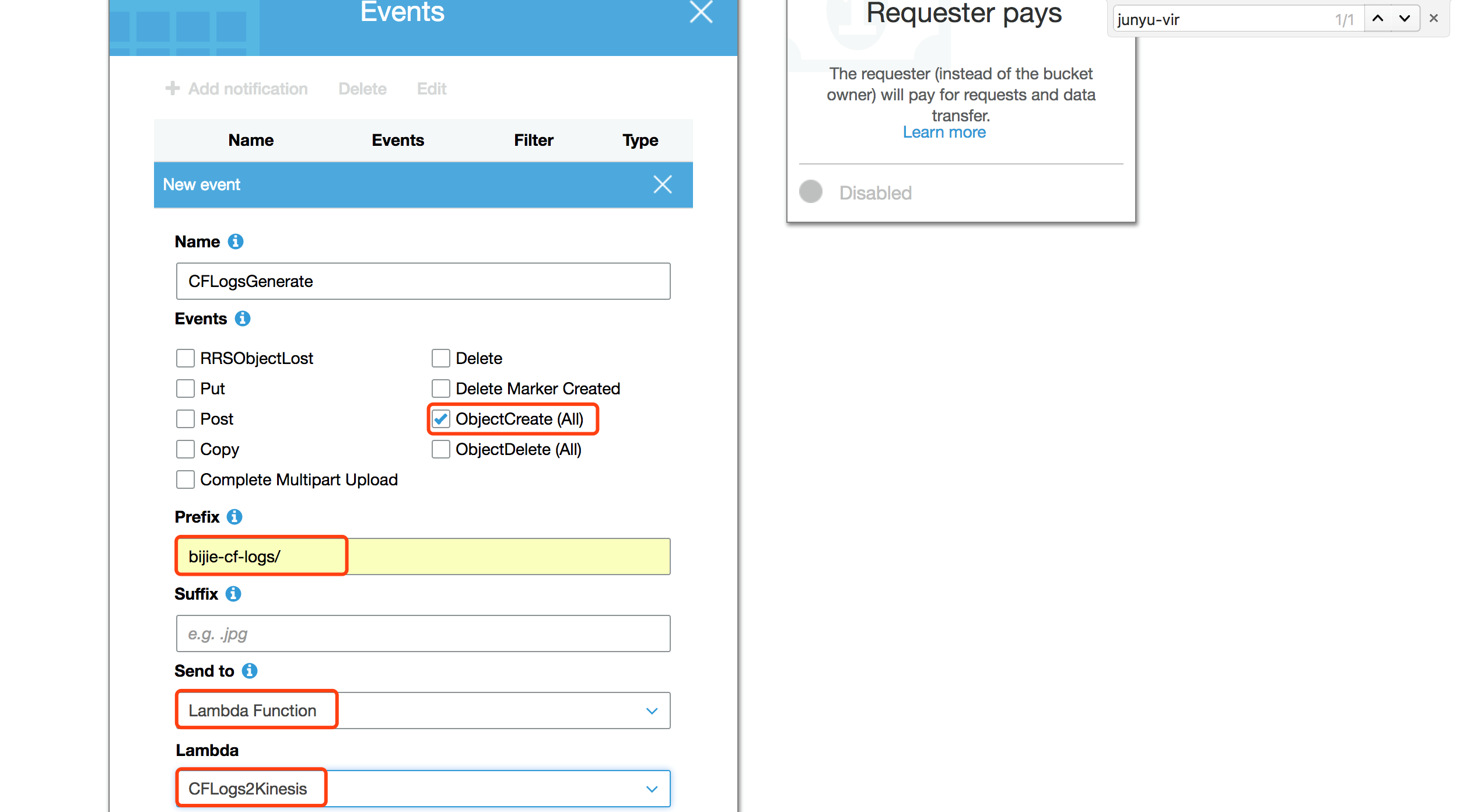
创建Lambda函数,用于解析CloudFront日志并将日志打入Kinesis流中,Lambda代码可从如下地址下载:
https://github.com/iwasnobody/cflogs2analytics2ddb/blob/master/CFLogs2Kinesis.py 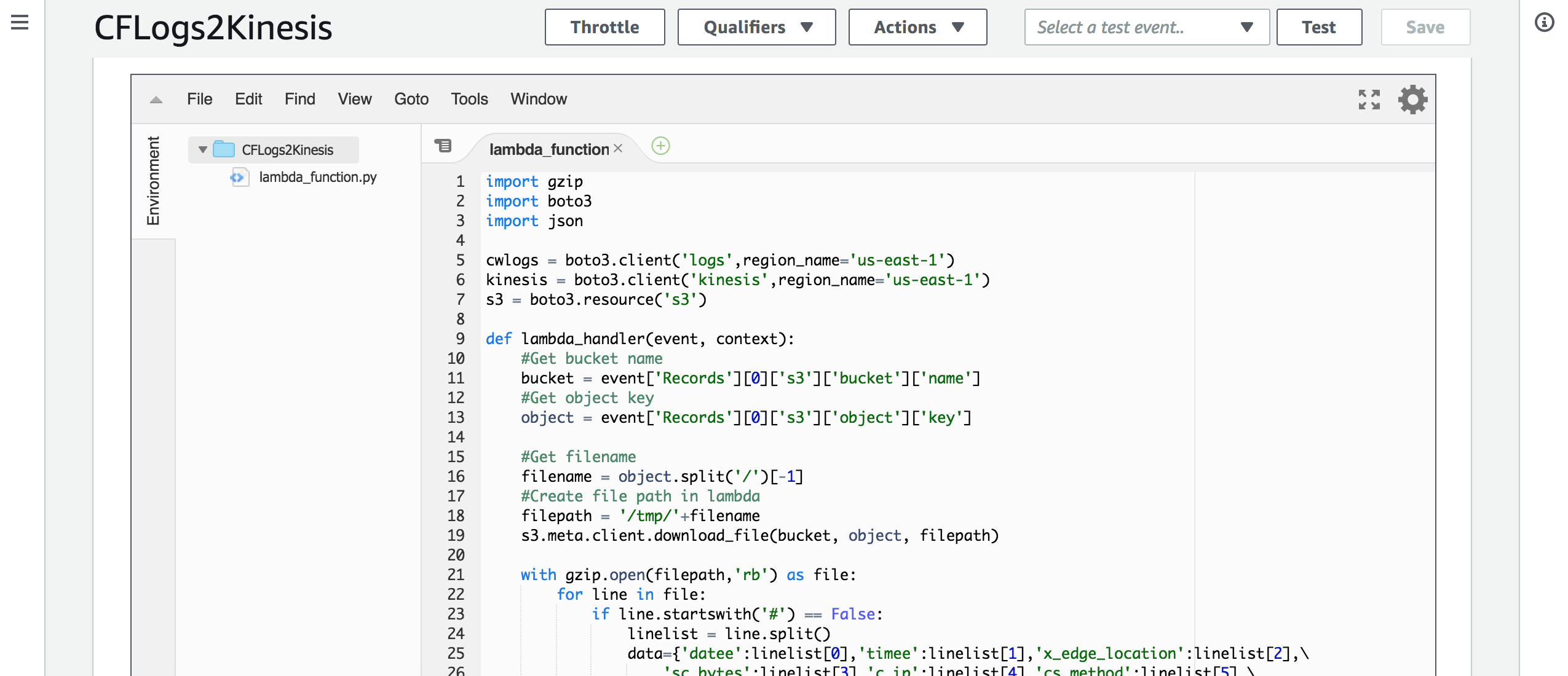
进入CloudFront日志保存的S3桶。
设置当有新日志文件产生的时候,触发之前创建Lambda函数。 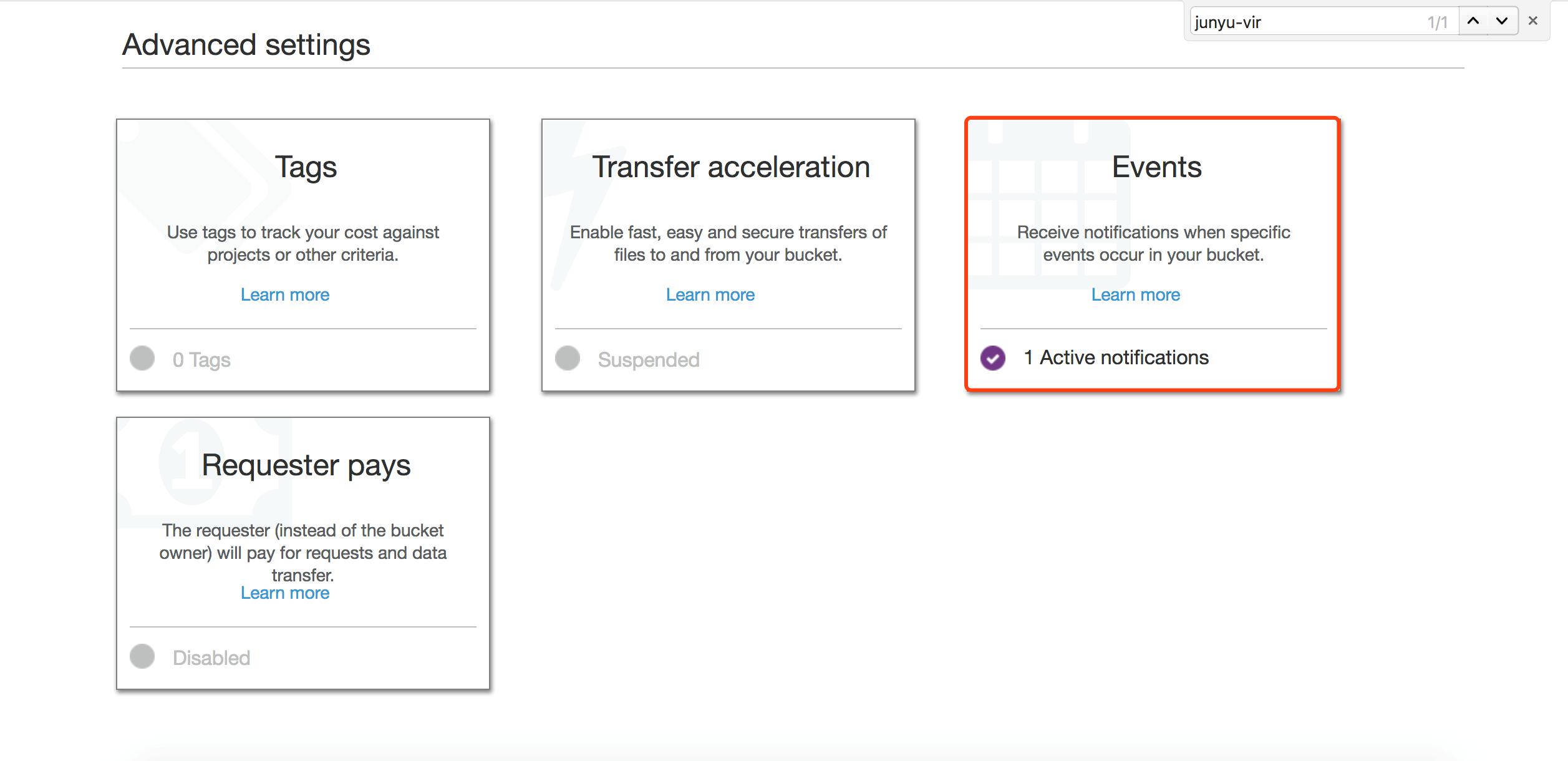
创建DynamoDB表,用于保存Kinesis Analytics分析的结果。

将创建的表设置成global table,与Ohio区域同步。

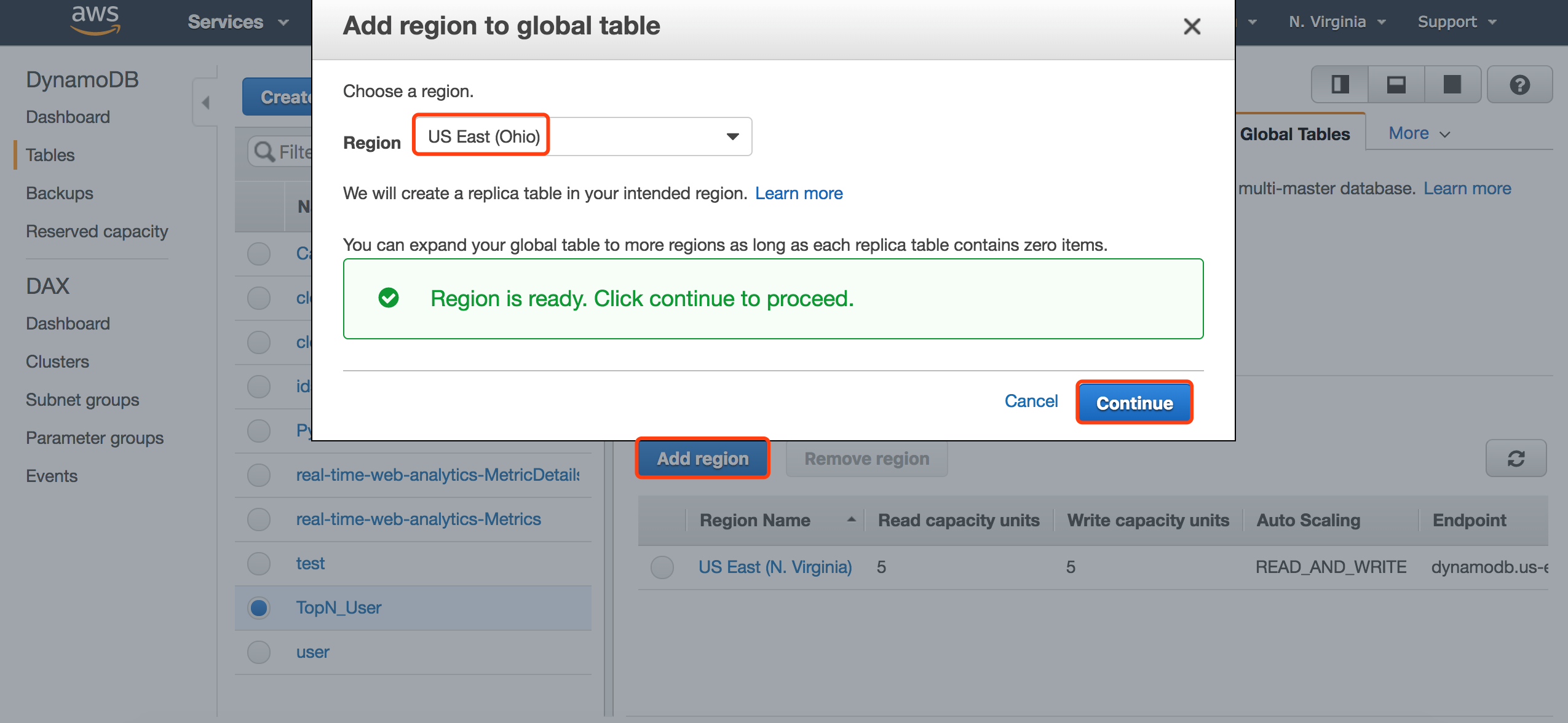
创建Kinesis Stream,用于接收Lambda发送过来的日志。
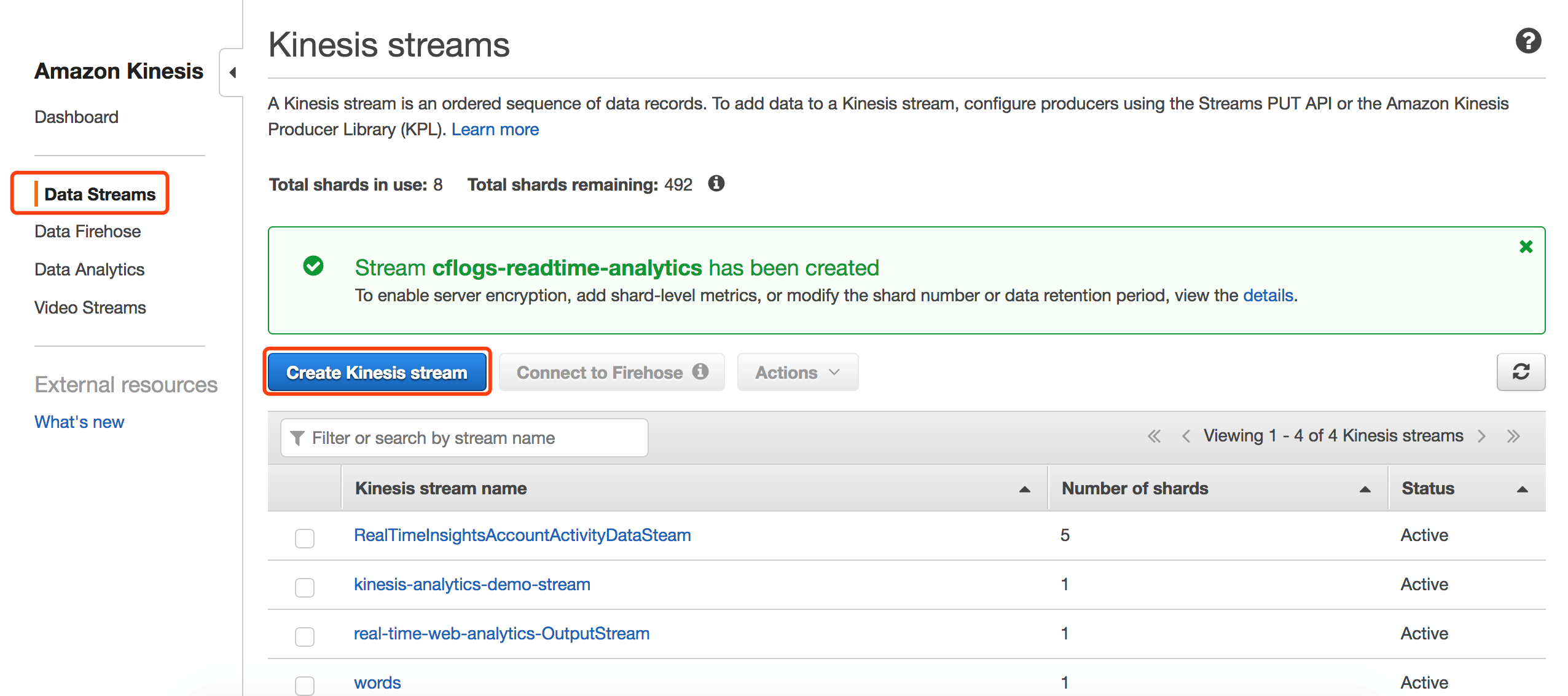
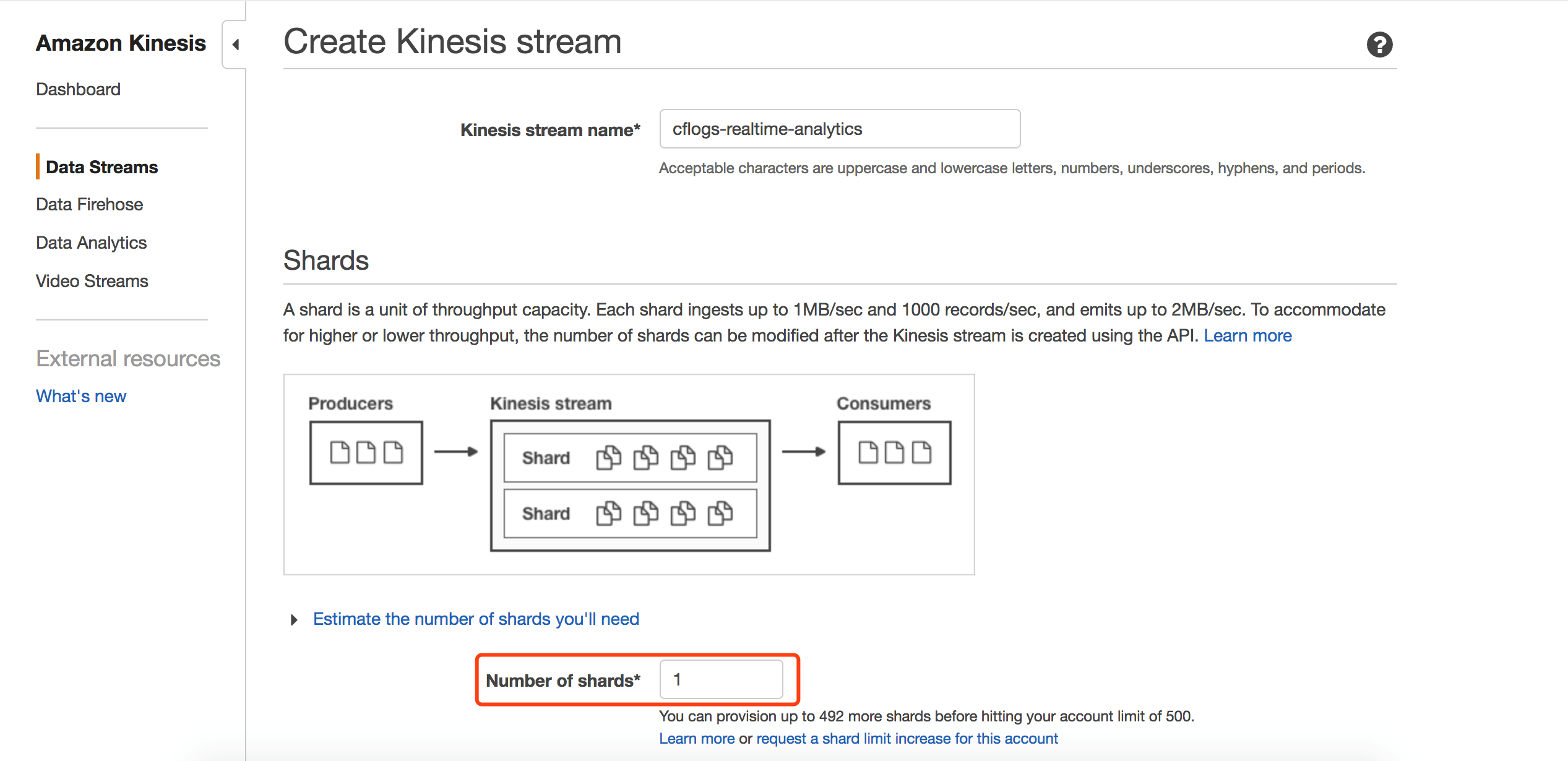
第二步 向Kinesis流中打入数据
由于CloudFront需要有用户访问流量的情况下才会产生日志,并且产生日志的过程不是实时的,所以为了便于测试,我们通过一个工具模拟Lambda产生的消息打入Kinesis流中,大家可以从如下链接查看该工具的详情。https://github.com/awslabs/amazon-kinesis-data-generator
Kinesis Data Generator通过PC端浏览器的简单配置,就能够快速地产生测试流量打入指定的Kinesis流中,并且支持产生一定随机的数据,下图中,我们将数据以每秒一条的速度打入us-east-1区域的Kinesis流,数据的格式模拟Lambda函数的输出,即:以JSON格式输出CloudFront日志的每个字段,并且c_ip客户端ip字段通过简单的设置,让工具以一定的比例生成4个ip地址中的一个,其他字段都为固定字段,测试数据可以通过让CloudFront产生日志后,在Lambda函数中输出获得,或者从如下链接获取:
https://github.com/iwasnobody/cflogs2analytics2ddb/blob/master/KinesisDataGenerator
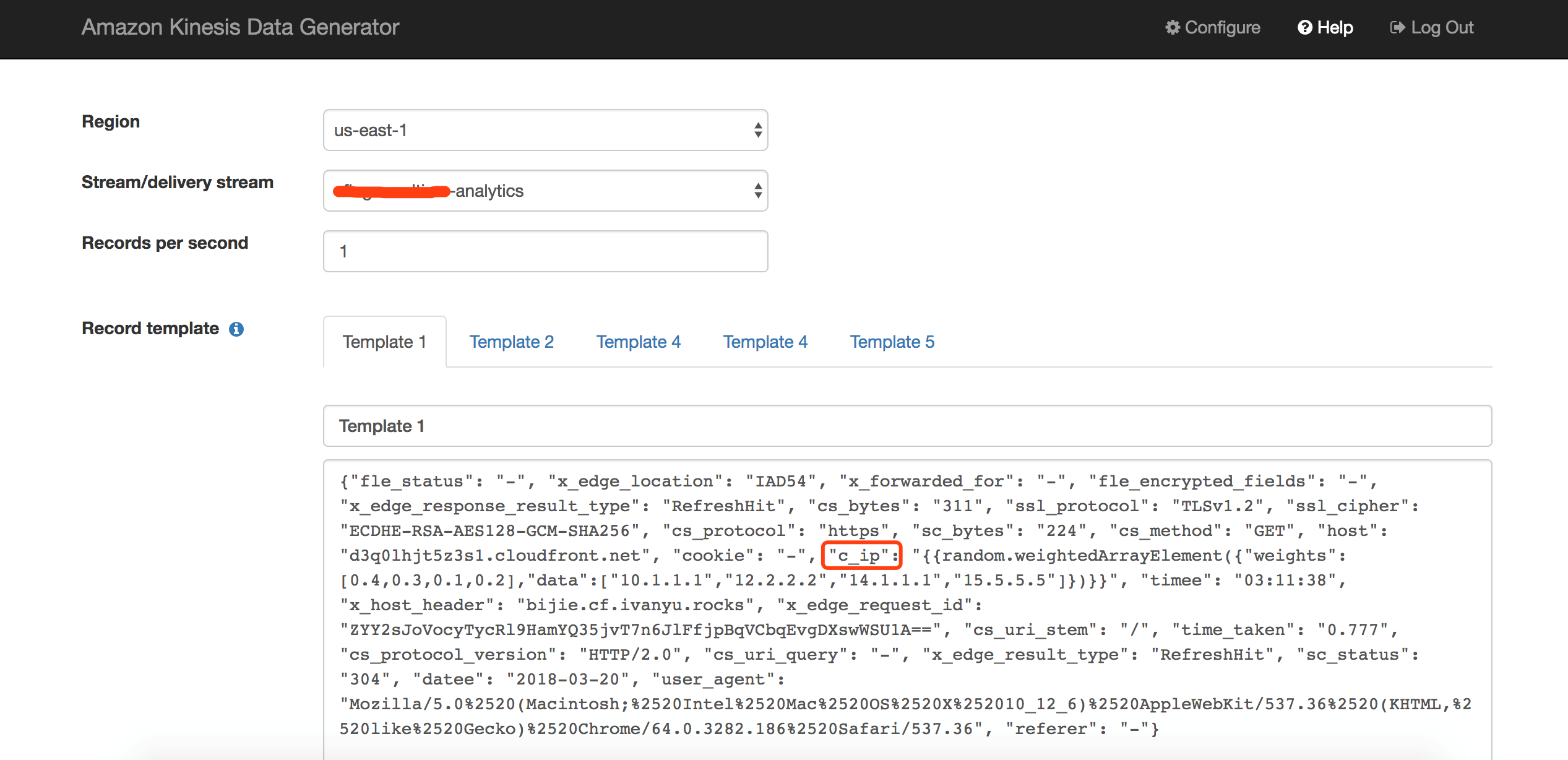
点击发送数据,开始将数据打入Kinesis流中。

第三步 创建Kinesis Analytics,对Kinesis流中的数据做实时分析
首先创建一个Data Analytics应用。
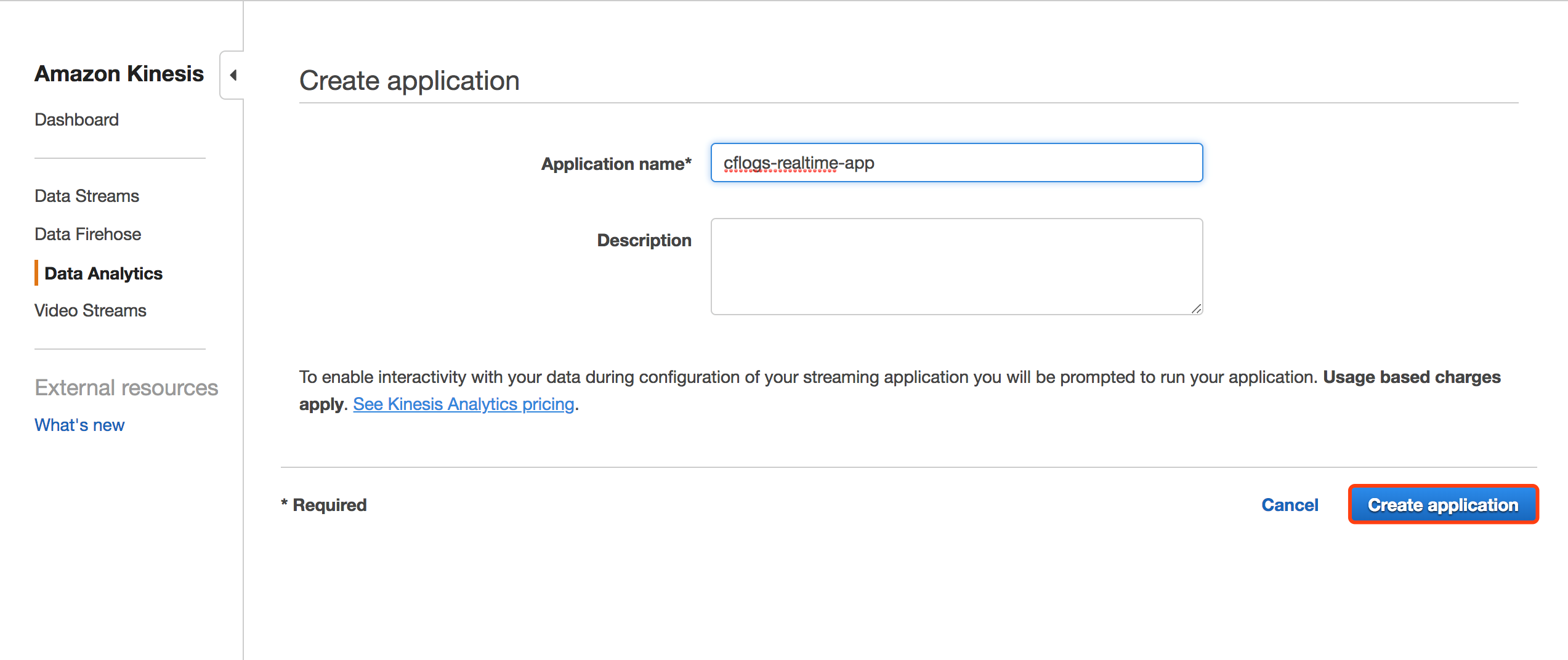
设置应用对接的数据源为之前创建的Kinesis流。
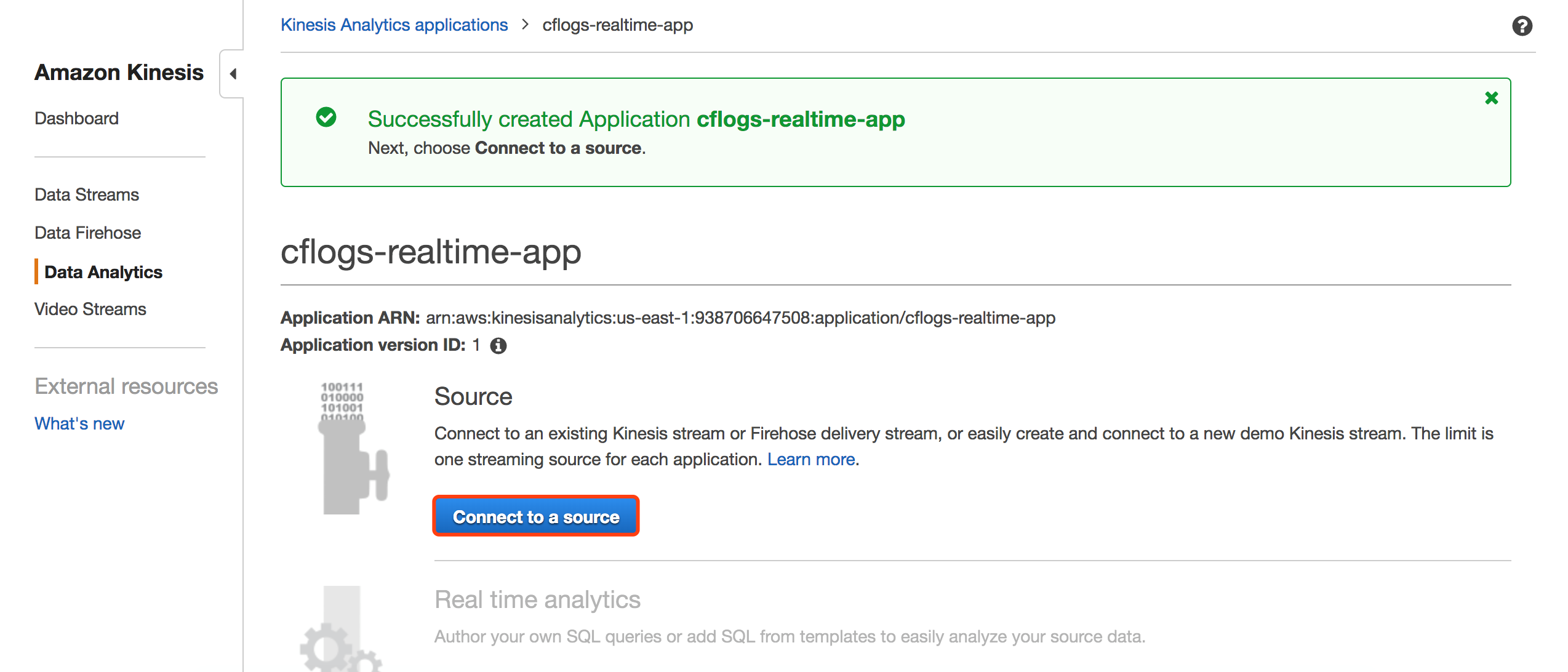

点击Discover schema,让Analytics自动发现Kinesis流中已有数据的schema。
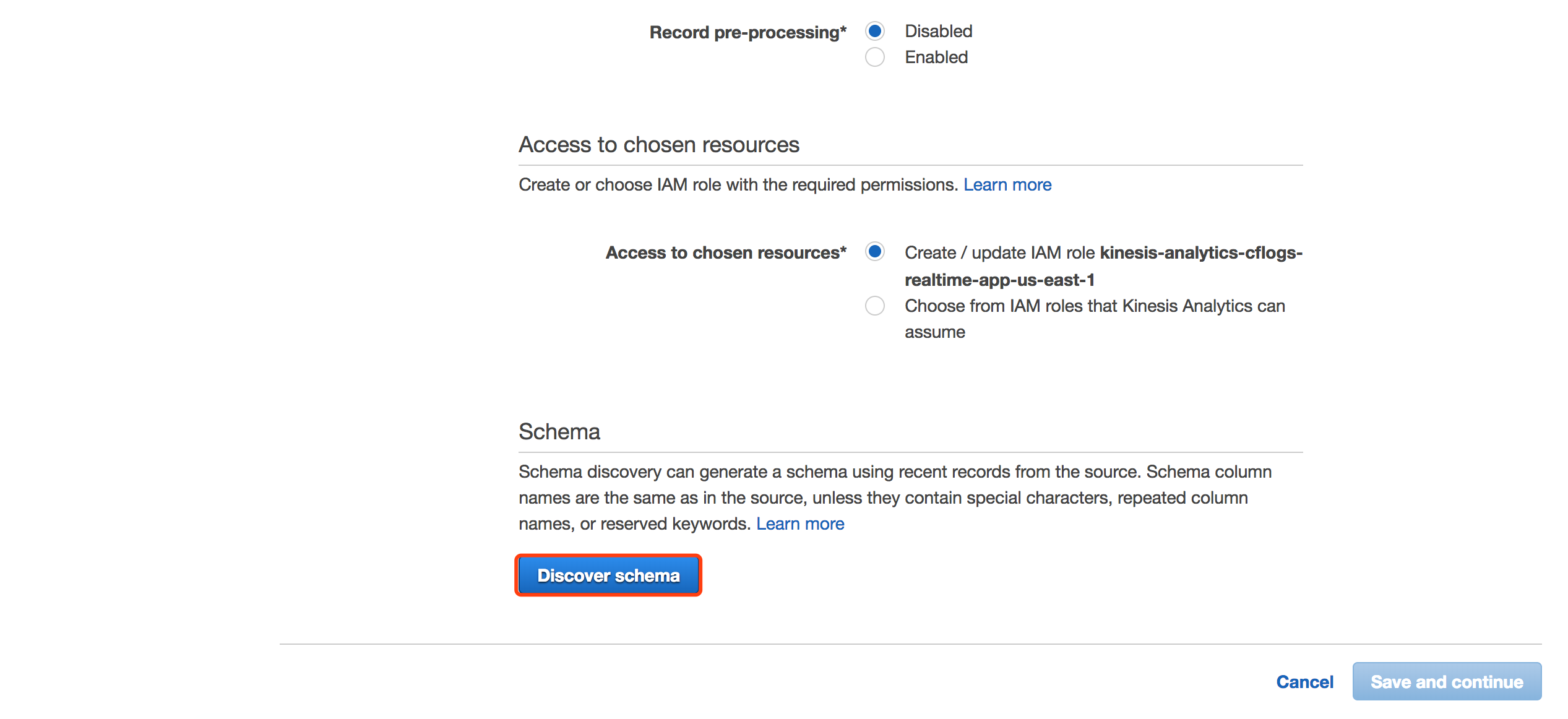
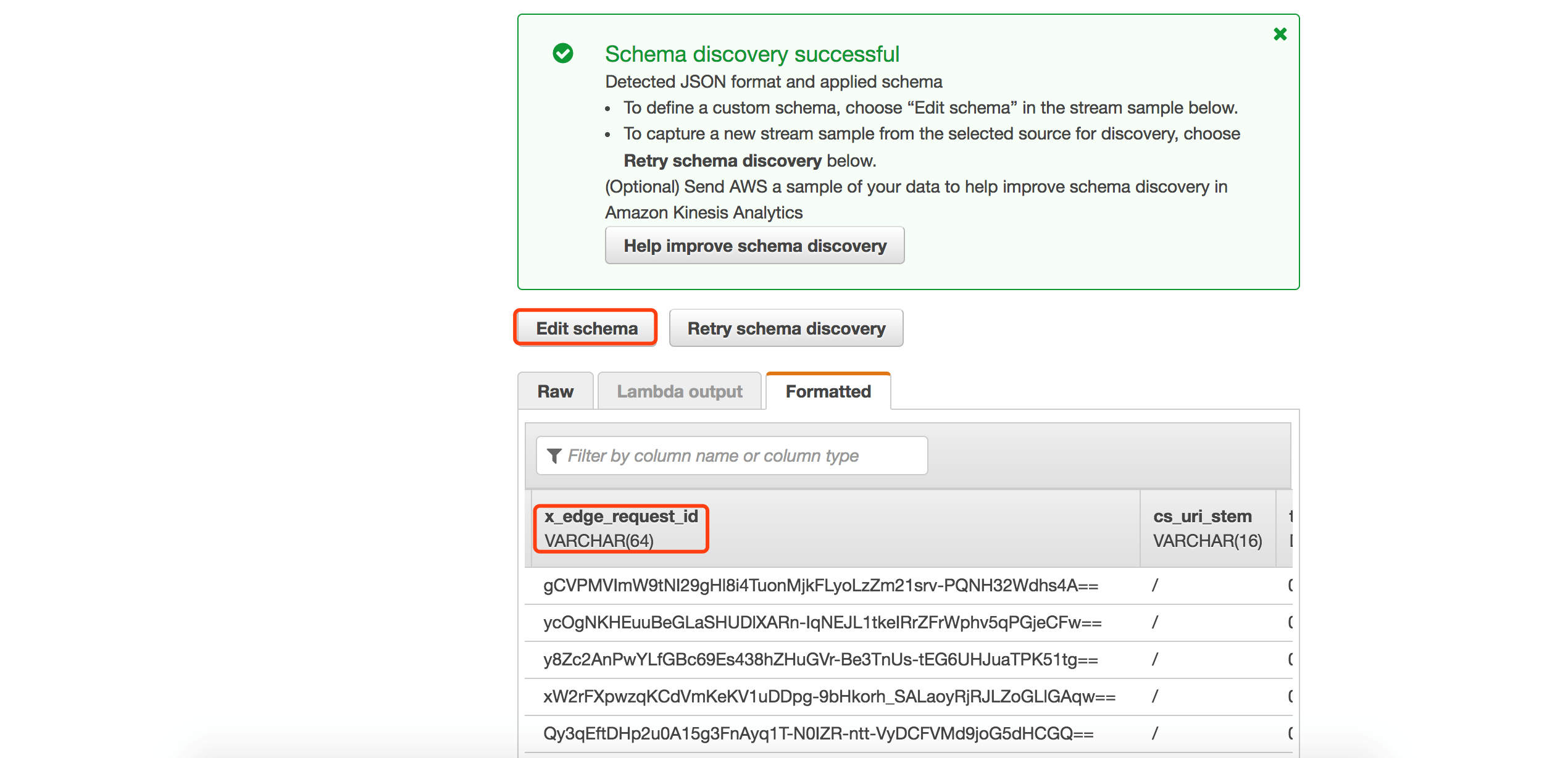
可以看到,Analytics可以自动帮我们识别JSON格式的CloudFront日志,但是由于我们打入的日志数据大部分数据为固定字段,所以自动识别的schema未必准确,比如:对于x_edge_request_id字段,varchar(64)可能过小,我们点击修改schema。
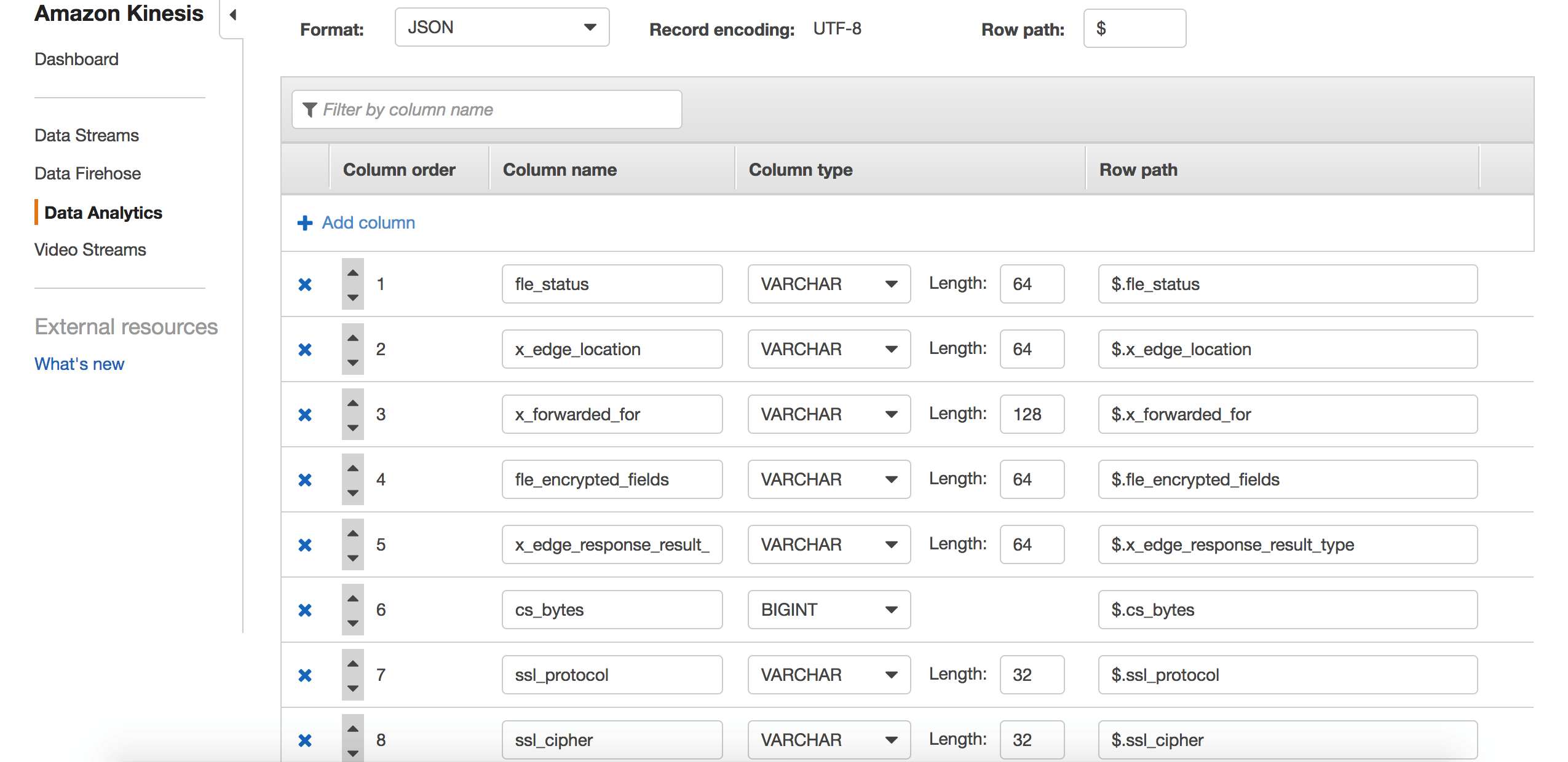
将schema做如下调整:
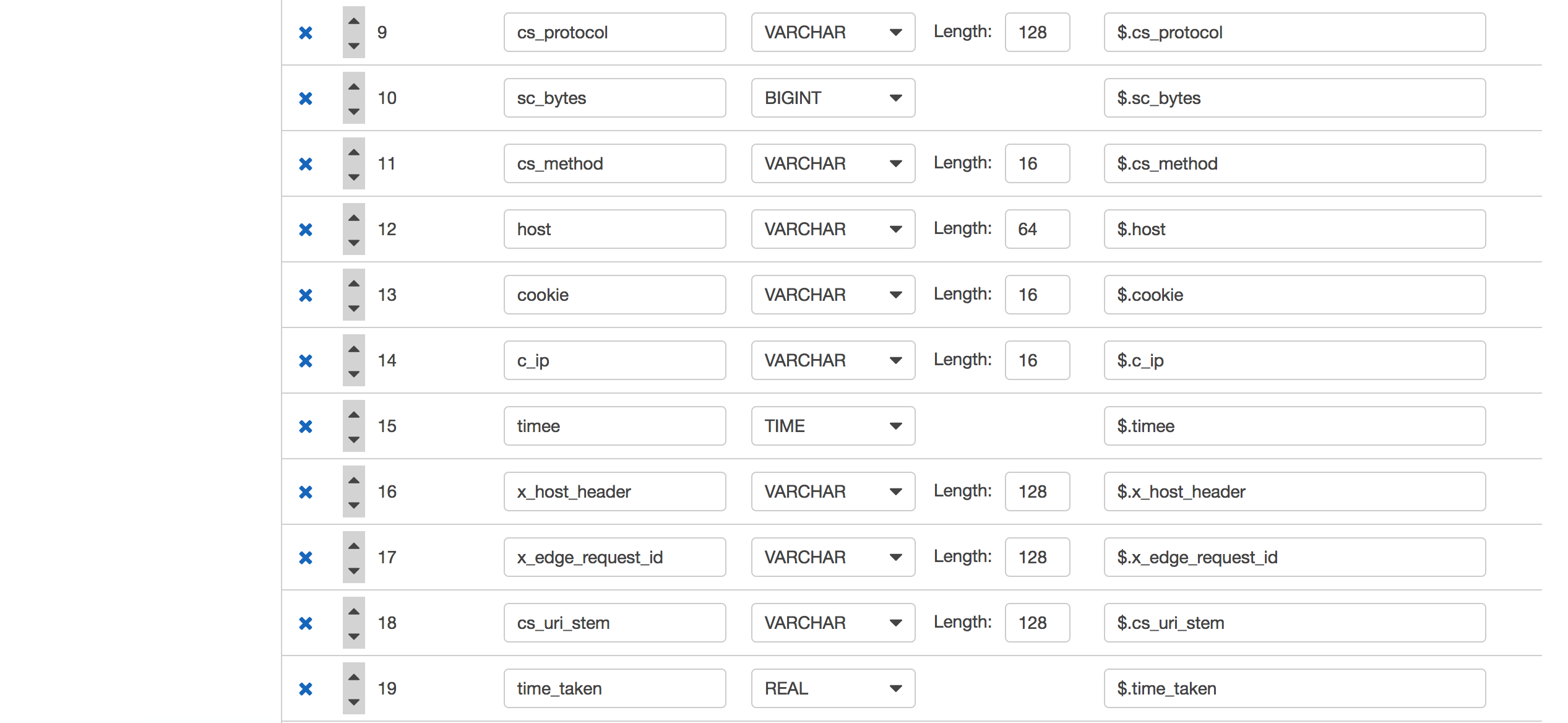
 点击Save schema and update stream samples,查看各个字段类型及长度已经修改成功,点击Exit返回上一步。
点击Save schema and update stream samples,查看各个字段类型及长度已经修改成功,点击Exit返回上一步。
点击Save and Continue继续。
下面,我们开始使用SQL语句对带有schema的流式数据做分析汇聚。
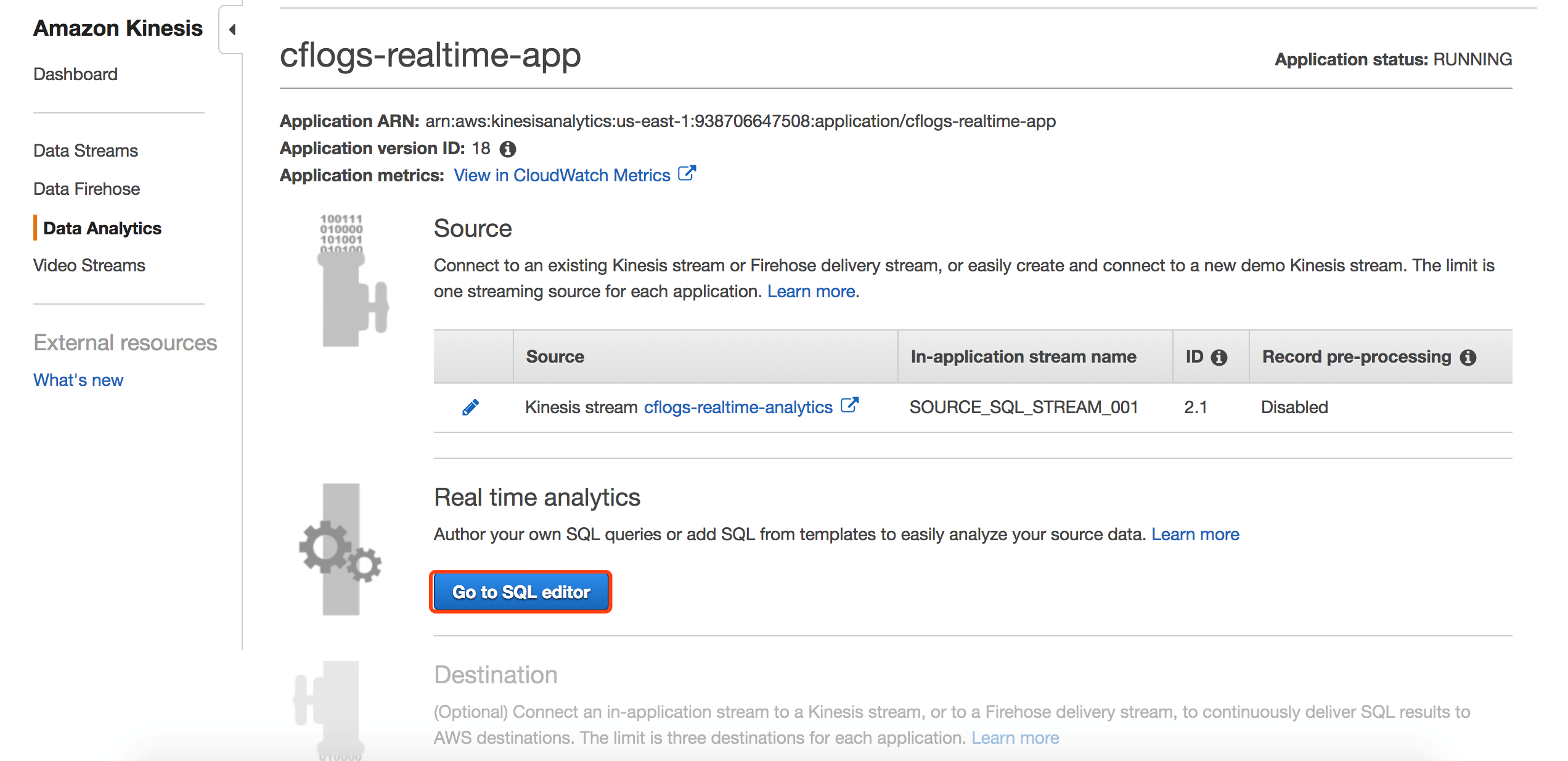
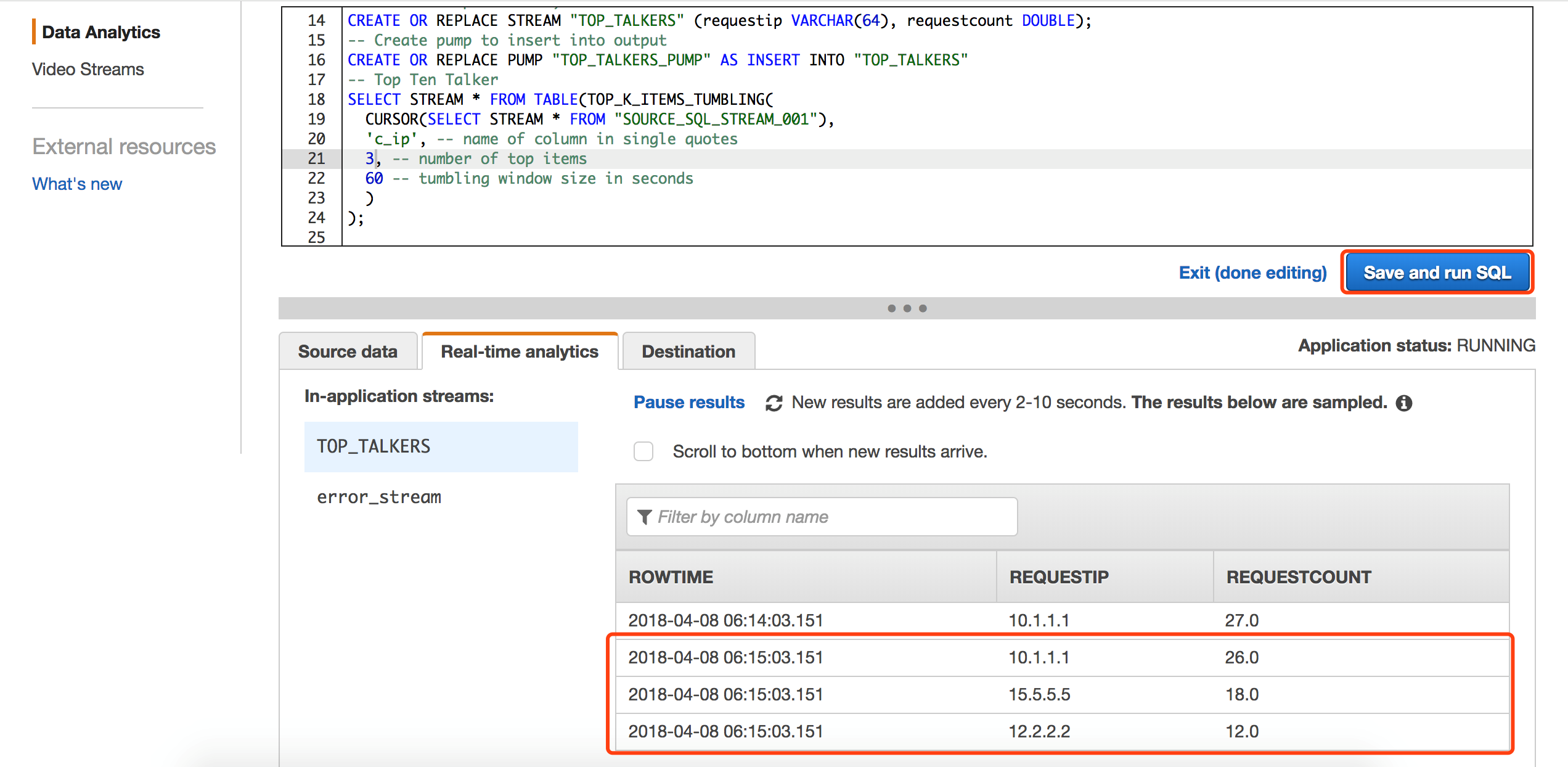
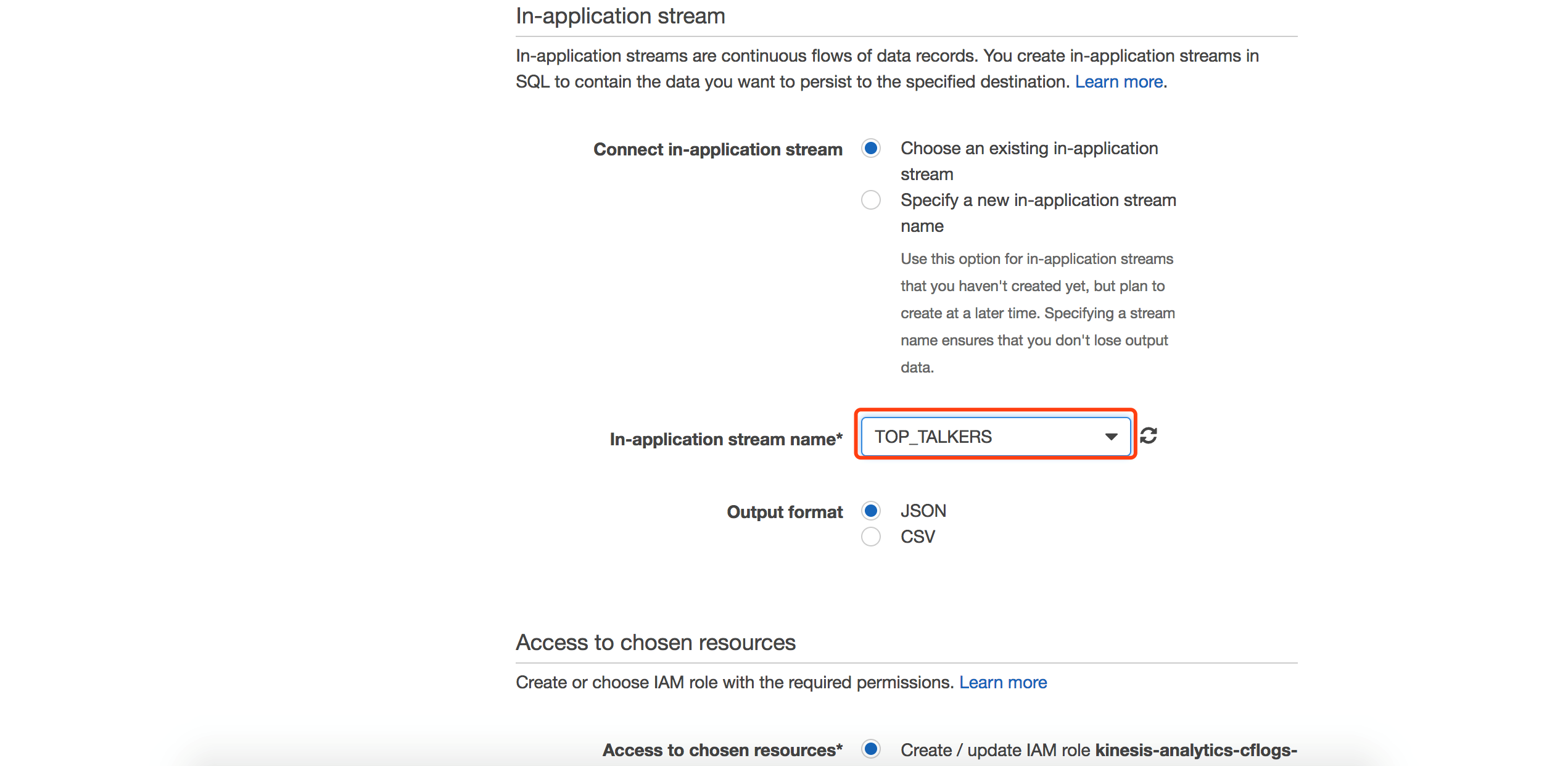
下面的SQL语句以1分钟为时间窗口,分析出1分钟内,访问CloudFront的Top3的用户ip地址,Kinesis Analytics的窗口可以实时观察到每分钟分析的结果,非常利于调试。
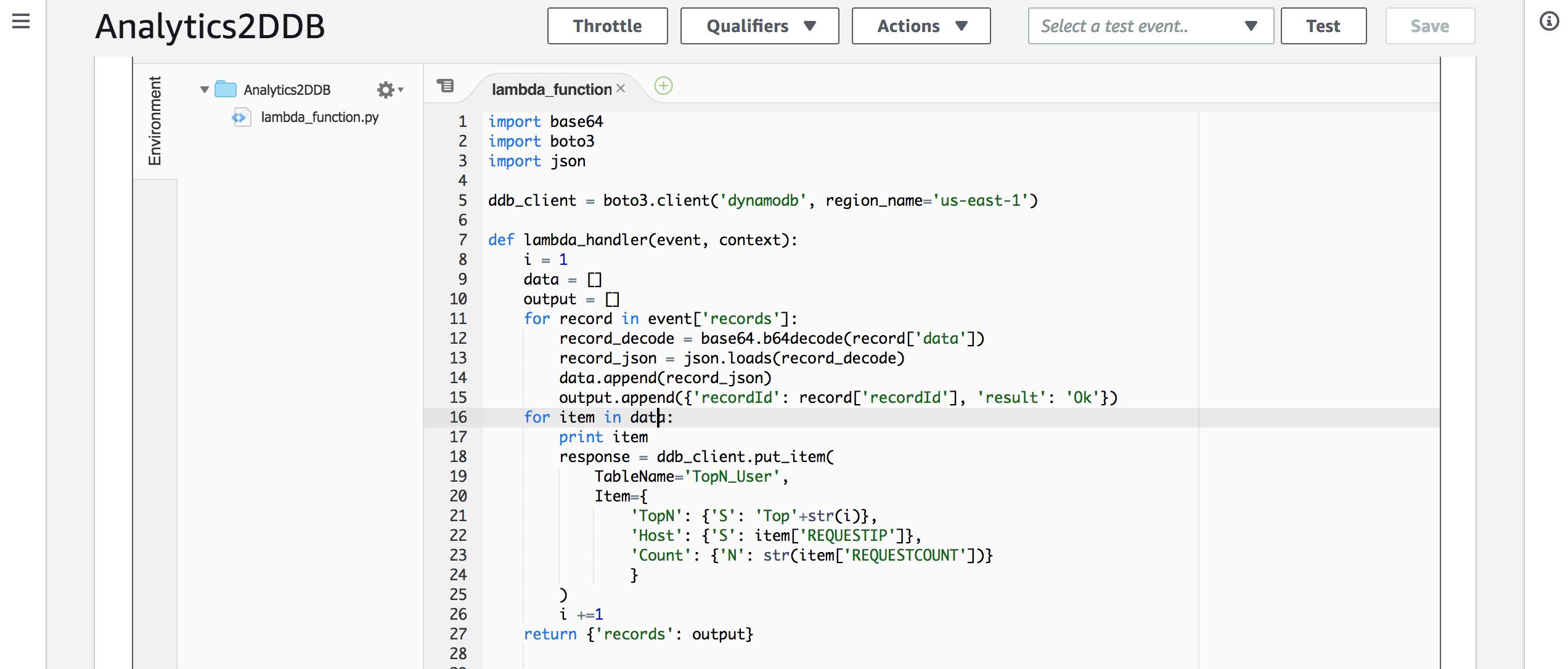
再继续配置Kinesis Analytics将分析结果输出之前,我们先来配置Lambda函数,用于接收输出结果,并将结果保存到DynamoDB中,Lambda代码可以从如下链接获取:
https://github.com/iwasnobody/cflogs2analytics2ddb/blob/master/Analytics2DDB.py
注意:根据输出结果的大小,需要调整Lambda函数的timeout时长。
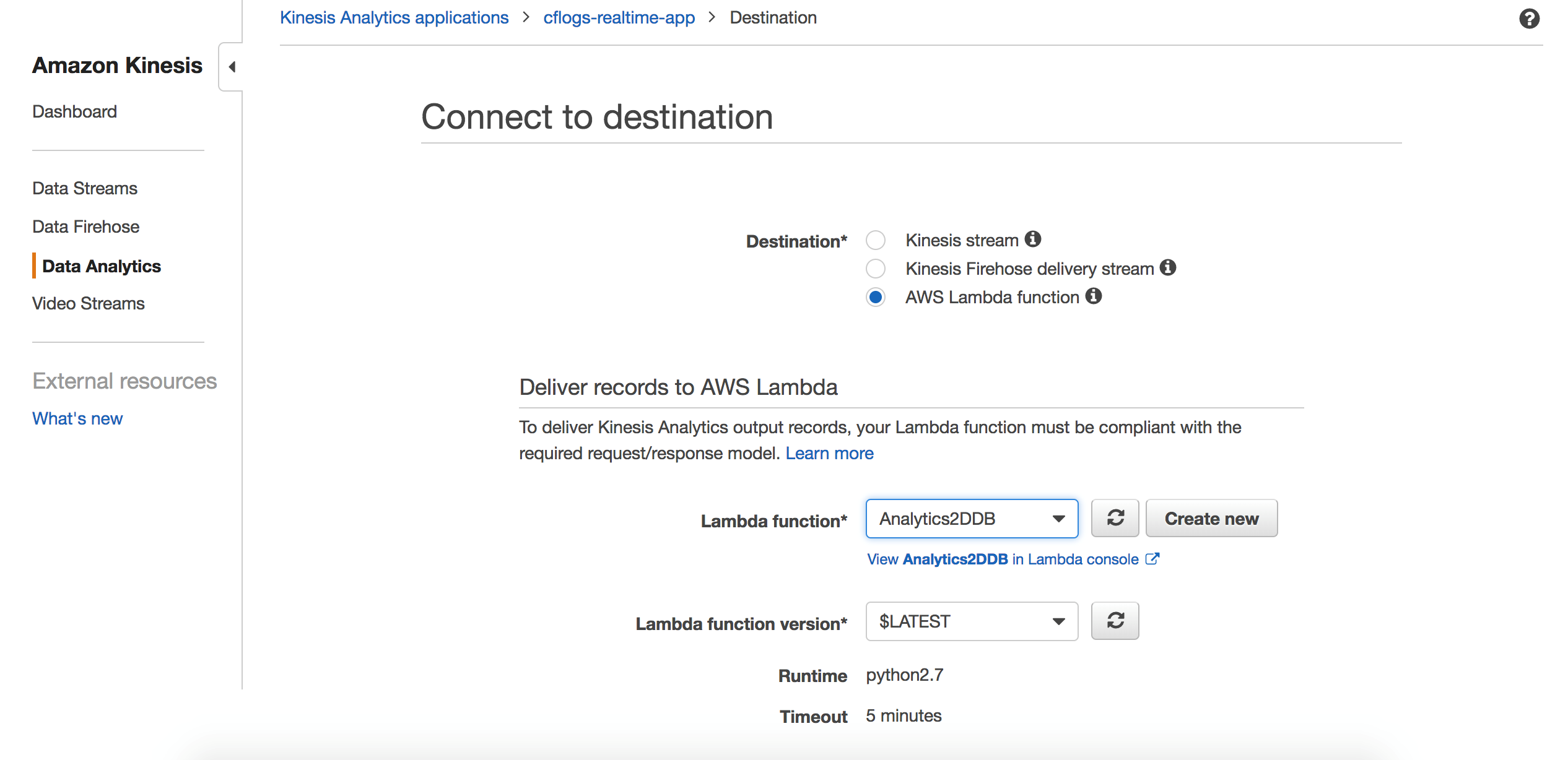
接着我们回到Kinesis Analytics界面,配置应用对接的输出。
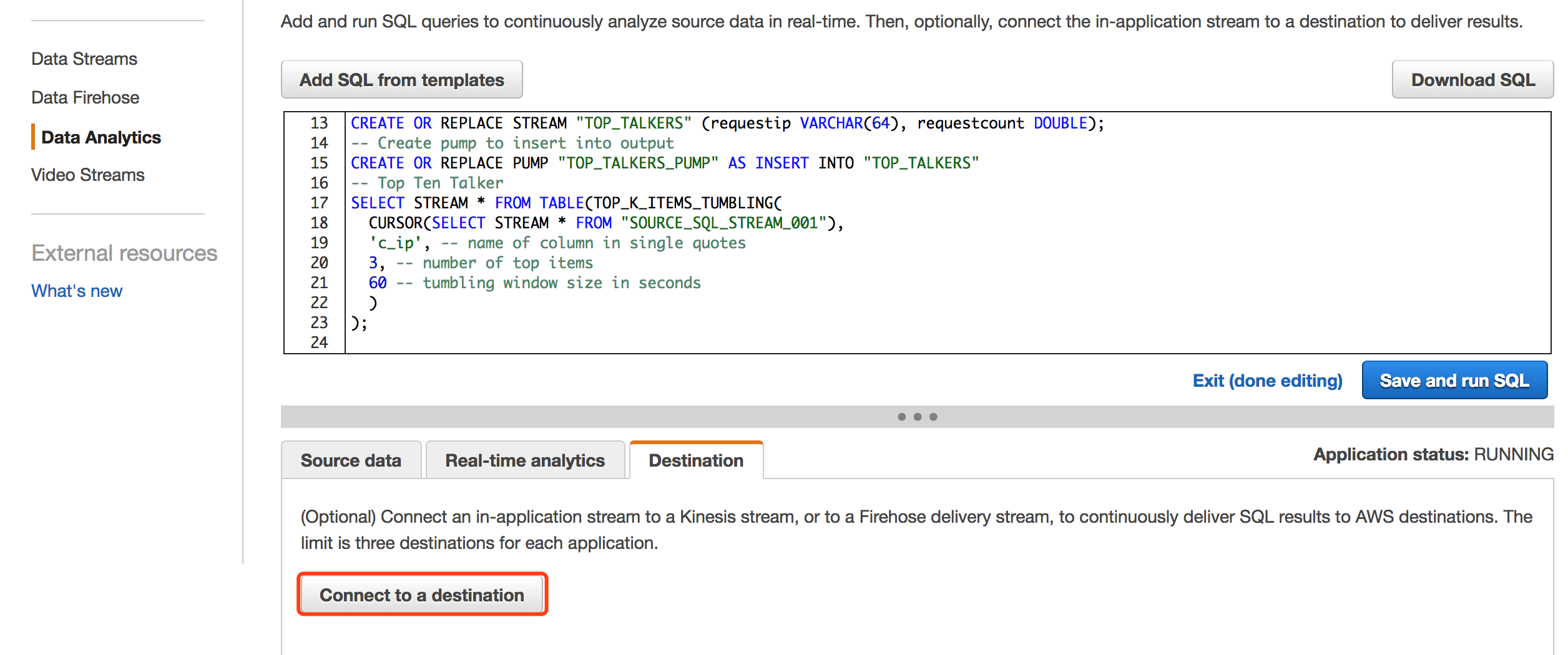
设置上面创建Lambda函数接收输出结果。
第四步 查看分析结果
我们可以进入到DynamoDB中,查看之前创建的表,不断地刷新,查看表中数据的变化。
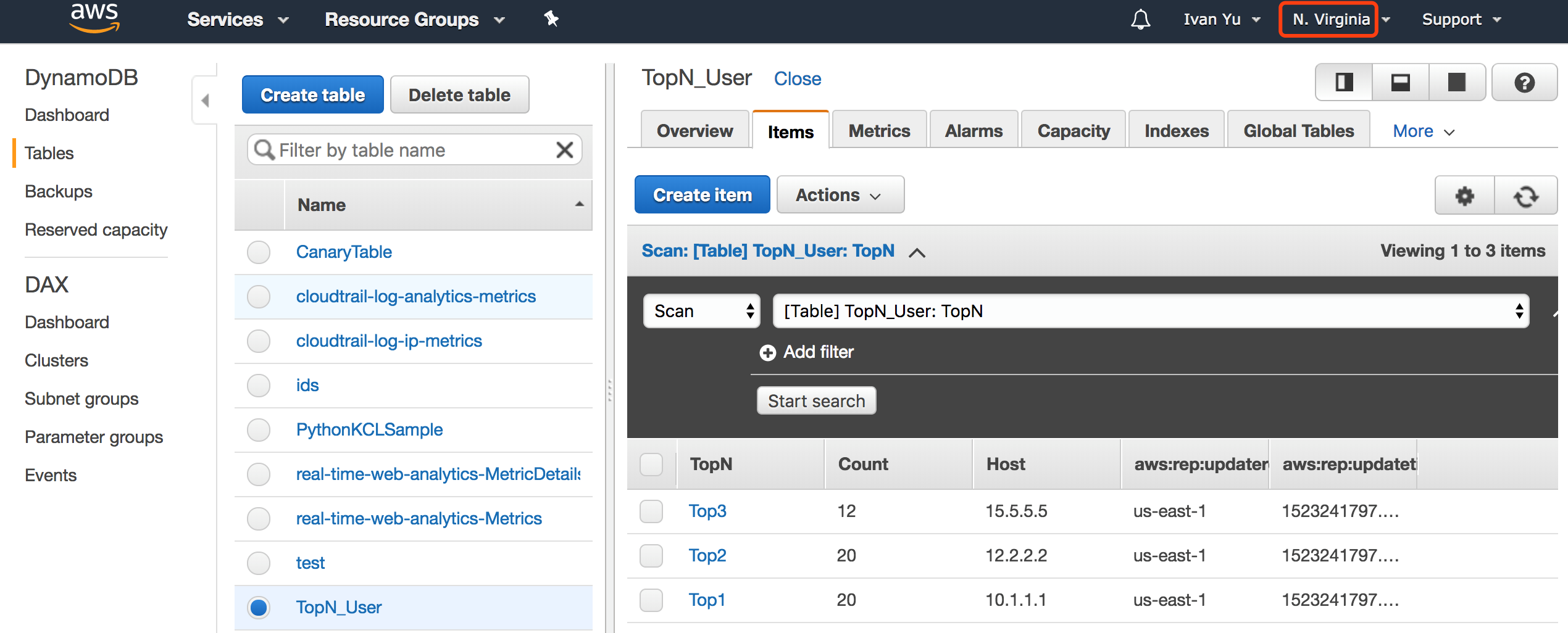
同时进入到Ohio区域,查看数据已经被同步过来了。